Web Scrapping đơn giản với HTMLUnit – Phần 2
Tác giả: Phạm Huy Hoàng
Mục đích: Chủ đề của bài viết này hướng dẫn cách thực hiện Web Scrapping (Parse dữ liệu từ website) trong các ứng dụng thực tế. Tiếp tục từ phần 1, ở phần này, chúng ta sẽ tái sử dụng lại bộ parser chúng ta đã viết để sử dụng với nhiều trang web khác nhau
Web Scrapping đơn giản với HTMLUnit – Phần 2
Tác giả: Phạm Huy Hoàng
Mục đích: Chủ đề của bài viết này hướng dẫn cách thực hiện Web Scrapping (Parse dữ liệu từ website) trong các ứng dụng thực tế. Tiếp tục từ phần 1, ở phần này, chúng ta sẽ tái sử dụng lại bộ parser chúng ta đã viết để sử dụng với nhiều trang web khác nhau
Yêu cầu về kiến thức cơ bản
- Nắm vững khái niệm về ngôn ngữ lập trình Java, lập trình thao tác hướng đối tượng, sử dụng các method hay function
- Nắm vững khái niệm về cách sử dụng XPath (tham khảo lại bài Giới thiệu về XPath http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xpath.html )
- Nắm vững và đã sử dụng tốt cách truy vấn sử dụng Xpath
- Có kiến thức cơ bản về HTML, javascript (Ko cần CSS).
- Đã hoàn thành phần 1 của bài hướng dẫn (tham khảo lại bài Web Scrapping đơn giản với HTMLUnit http://www.kieutrongkhanh.net/2016/08/web-scrapping-on-gian-voi-htmlunit.html )
Tools sử dụng:
· Netbeans 6.9.1
· JDK 6 update 22
· Trình duyệt: Chrome hoặc Firefox
· Thư viện: HtmlUnit
Chúng ta quay trở lại với project cũ cuối bài trước. Chúng ta tạo thêm 2 package mới là parseInfo và parse.
ParserInfo là class để chứa thông tin hỗ trợ việc parse trang web. Ta tạo interface cho parser và parserInfo


Quý vị tạo đầy đủ các class như trong hình.
Để parse dienmay.com, ta tạo 1 class DienMayParseInfo, implement interface WebParseInfo


Ta copy những đoạn Xpath cũ, thay vào các hàm tương ứng.
Tiếp theo, ta viết class SimpleWebParser, thực hiện implement interface WebParser

Với nhiều trang web, có thể javascript bị lỗi những website vẫn chạy bình thường, do đó ta phải set ThrowExceptionOnScriptError để hệ thống không throw Exception.
Lấy toàn bộ categories của trang

Lấy product dựa theo category


Đôi khi, chúng ta không cần lấy toàn bộ các category, mà chỉ lấy 1 vài category, do đó ta overload hàm getProducts, 1 hàm lấy toàn bộ, 1 hàm truyền tham số vào

Add all tức là add toàn bộ entry của list nào vào list kia

Sau khi đã viết xong, chúng ta tạo class Main mới, thực hiện lại việc parse dienmay.com. Code bây giờ đã ngắn + đơn giản hơn nhiều.

Kết quả:


Thử lấy toàn bộ product.

Kết quả:


Như chúng tôi đã thuyết minh, toàn bộ những việc select element của chúng ta thực hiện bằng cách đưa chuỗi Xpath vào. Do đó, khi muốn parse 1 trang web mới, chúng ta chỉ cần thay đổi chuỗi Xpath đó, tức là đổi object WebParseInfo, không cần phải viết thêm bất cứ dòng code xử lý parsing nào.
Chúng ta tiếp tục với trang web thứ 2: vatgia.com

Tiếp tục xác định chuỗi Xpath tương ứng để select. Những chuỗi xpath nào đơn giản chúng tôi sẽ không giải thích nữa.
Xpath Category link

Trang vatgia.com có 2 kiểu show products, do đó câu lệnh xpath khó hơn, để có thể select được toàn bộ hàng hóa của 2 kiểu
Kiểu 1

Kiểu 2

Test thử chuỗi Xpath đầu tiên, nhận đc kiểu 1 nhưng không nhận đc kiểu 2


Quan sát ta thấy, sản phẩm trong kiểu 2 nằm trong div có class =”block masonry-brick”. Ta sửa lại chuỗi Xpath mới, nhận được cả 2 kiểu


Quan sát cấu trúc HTML, ta tiếp tục viết chuỗi Xpath để tìm ra product link và image link


Tiếp theo là chuỗi Xpath về name và price


Từ các chuỗi Xpath đã viết được, chúng ta tạo class VatGiaParseInfo, implement interface WebParseInfo


Sửa lại hàm main, bắt đầu chạy thử (Vì các class đều kế thừa interface nên chúng ta có thể thay đổi dễ dàng).

Kết quả:


Lỗi xảy ra khi chúng ta parse Category “Dịch vụ, Giải trí”

Ta sửa lại chuỗi Xpath price, chạy lại

Sở dĩ chúng ta chỉ lấy đc 47 hàng hóa cho mỗi categories vì website vatgia.com có thực hiện paging, mỗi trang chỉ show 47 sản phẩm.
Việc parse website có paging v…v sẽ được hướng dẫn trong phần 3 của bài viết.


Parse phần bất động sản vẫn hiện parse error, nhưng vì data phần Bất Động Sản phù hợp với Product nên chúng ta không quan tâm.
Website tiếp theo chúng ta thực hiện parsing là: http://www.thegioididong.com/

Xác định Xpath của thanh navigation

Xpath của Div chứa sản phẩm. Cấu trúc sản phẩm của thegioididong hơi phá cách, lại chèn thêm quảng cáo, việc tìm đúng câu Xpath khá khó khăn. Để ý kĩ ta thấy những div sản phẩm có attribute data-webstatus = 4, div quảng cáo có data-webstatus = 9, từ đó lọc ra.

Tiếp tục nghiên cứu HTML, chúng ta sẽ thấy cấu trúc HTML của những sản phẩm 1 ô khác cấu trúc HTML của những sản phẩm 2 ô, câu lệnh XPAth phải chọn đc cả 2
Sản phẩm 1 ô

Sản phẩm 2 ô

Rút ra câu lệnh Xpath cuối cùng (dài ghê chưa)

Câu lệnh Xpath để lấy link lại khá đơn giản

Tương tự với câu lệnh Xpath lấy name

Cấu trúc giá dùng chung nên câu lệnh lấy price cũng ko phức tạp

Sau khi đã test các câu lệnh Xpath, chúng ta tiếp tục viết class ThegioiDDParseInfo


Câu lệnh Xpath getName hơi khác 1 chút so với câu lệnh gốc
Tiếp tục run thử, ta được

Chỉ có 7 categories đầu là hàng hóa.


Số lượng Product parse được ít hơn so với ta nhìn thấy. Vì tgdd có sử dụng ajax để load động + paging động. Việc kích hoạt Ajax + hỗ trợ load động HtmlUnit có hỗ trợ, chúng tôi sẽ hướng dẫn điều này ở phần tiếp theo.
Trang Web cuối cùng chúng ta parse thử lần này là: http://www.worldsoccershop.com/

Để đơn giản, chúng ta không parse theo category hàng (Vì trong mỗi category lại có category con), mà chúng ta parse theo club. Parsing website này cũng khá đơn giản vì nó không có cả ajax lẫn paging.
Mỗi club ta xem như 1 category, tìm ra chuỗi Xpath

Chuỗi Xpath cho product

Xpath cho image, name, product link



Quý vị để ý kĩ phần price, vì có nhiều product chỉ có 1 price, nhiều product có tới 2 price

Do đó ta sửa lại chuỗi Xpath

Công việc cuối cùng, viết class WorldSoccerShopParseInfo


Chạy thử. Do mạng của tôi kết nối tới trang này khá chậm nên tôi chỉ parse 5 club đầu
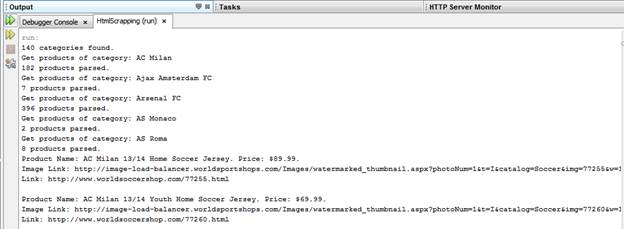

Chúc mừng quý vị đã hoàn thành 2 bài hướng dẫn đầu tiên của loạt bài Web Scrapping với HtmlUnit.
Nội dung part 3 sẽ hướng dẫn cách parse ở những trang có paging, loading ajax, cùng với việc download hình về máy trong khi parse.
Cảm ơn quý vị đã theo dõi và ủng hộ bài viết.
Đã có phần 3 chưa thầy? Đọc bài viết thấy hay và hữu ích quá, mong thầy sớm cập nhật phần 3.
Trả lờiXóaMong phần 3 quá, mà 4 năm rồi thầy chưa cập nhập lại.
Trả lờiXóa