Sử dụng XML Parser trích xuất dữ liệu từ website và sử dụng JAXB để lưu trữ các giá trị này trong việc xử lý của ứng dụng
Tác giả: Lương Công Thuận
Mục đích: bài viết này hướng dẫn khai thác thông tin có sẵn trên các website (các web này không sử dụng jquery hay javascript để tạo front end tương tác với người sử dụng) thay vì nhập liệu theo cách truyền thống. Bài viết sử dụng bộ StAX parser để parse hay phân tích dữ liệu của trang HTML và chuyển thành dữ liệu có cấu trúc. Cách thức này hỗ trợ việc thu thập dữ liệu tự động từ trang các web như là chứng khoáng, thời tiết, sản phẩm, tin tức, …
Trước khi tiếp cận phương pháp này, chúng ta cần biết việc đăng ký bảng quyền của một số website. Việc đăng ký này giúp các trang web bảo vệ dữ liệu của họ. Ví dụ như chính sách bảo mật của 123phim.vn

Bài viết này sẽ trình bày các bước tiếp cận để chúng ta có thể sử dụng dữ liệu trên Internet một cách hợp pháp.
Kiến thức yêu cầu
· Nắm vững các khái niệm về XML cùng với các định nghĩa well-form, validate
· Nắm vững các khái niệm về HTML, XML DOM trong JavaScripts
· Nắm vững các khái niệm về ngôn ngữ lập trình Java, lập trình thao tác hướng đối tượng
· Tool được sử dụng trong bài viết là Netbeans IDE 7.4 kết hợp với JDK 7 update 51.
Kiến thức tổng quát
· StAX – là bộ parser thực hiện parsing tài liệu XML theo cơ chế như sau
o Khi tài liệu XML được đưa vào bộ parser, toàn bộ tài liệu được kiểm tra well-formed
o Khi nội dung tài liệu kiểm tra xong và đóng, toàn bộ tài liệu được truy cập dưới dạng Stream và được nạp vào bộ nhớ từng phần tùy theo tiến trình duyệt tài liệu
o Sau đó, bộ StAX parser sẽ thực hiện việc đọc các thành phần theo chiều đi tới trong stream tùy theo sự điều khiển của ứng dụng và lấy giá trị theo yêu cầu của người dùng
o StAX parser có đặc tính tối ưu là bộ parse dạng pull, nó cho phép người sử dụng điều khiển quá trình xử lý. Nó cung cấp khá năng cho người dùng có thể dừng bộ parser bất cứ khi nào, có thể bỏ qua một số phần tử nhất định, có thể tạm dừng quá trình parse, có thể tiếp tục quá trình parse đã dừng
o StAX parser hỗ trợ multitple thread đối với ứng dụng và hỗ trợ nhiều người sử dụng cùng một lúc
o Cú pháp API của StAX rất đơn giản bởi vì nó hỗ trợ di chuyển trong Stream và đưa ra dữ liệu dạng tổng quát nhất cho người sử dụng
o StAX là bộ parser duy nhất hỗ trợ cơ chế đọc và ghi trên tài liệu XML
o StAX hỗ trợ cơ chế đọc tài liệu XML cực kỳ lớn và hỗ trợ xử lý với tốc độ duyệt khá tốt và phù hợp với thiết bị có bộ nhớ nhỏ và ít.
· JAXB - Java Architecture for XML Binding
o Nhằm giảm thiểu việc phức tạp trong xây dựng bộ parser sử dụng DOM API và nhằm hỗ trợ việc trao đổi dữ liệu giữa các ngôn ngữ và cấu trúc khác nhau thông qua DTD và XML-Schema.
o Hai chức năng chính là marshall và unmarshall dữ liệu từ Java Object sand XML và ngược lại.
· Lưu ý về StAX trong bài viết này
o HTML
là một tài liệu XML không được well-form (VD:
thẻ input và meta không có thẻ đóng). Vì vậy,
khi sử dụng bộ parse StAX, chúng ta cần lưu ý cấu
hình để bộ parse không bị dừng khi gặp lỗi
không well-form.
(Xem chi tiết trong phần 3)
o StAX là bộ parse tài liệu XML có thể cung cấp những thông tin liên quan đến tài liệu HTML như: loại thẻ element theo tuần tự từ trên xuống từ trái qua, tên thẻ, giá trị thuộc tính của thẻ (nếu có). Vì vậy, để trích xuất được những dữ liệu cần thiết trên tài liệu HTML, chúng ta cần quan tâm đến vị trí và thuộc tính của thẻ chứa những dữ liệu đó trong tài liệu HTML.
Bước 1: Nghiên cứu dữ liệu cần truy xuất và nguồn trang cung cấp.
Trong bài này, chúng ta sẽ thu thập thông tin về thuốc (tên thuốc, hình ảnh, …). Do vậy, chúng ta sẽ tìm kiếm những trang web có liên quan về giới thiệu, hoặc kinh doanh sản phẩm thuốc. Ở đây, chúng tôi thực hiện ví dụ với website www.thuoctienloi.vn.
Ở bước tiếp theo, chúng ta cần xác định phần dữ liệu cần trích xuất. Ở đây, chúng ta cần thông tin là tên thuốc và hình ảnh cho nên chúng ta sẽ phân tích cấu trúc thẻ ở của một sản phẩm trên tài liệu HTML.
Trong bài viết này, chúng ta sẽ dùng dùng extension của Chrome (nhấn phím F12) để phân tích mã nguồn của tài liệu HTML. Ví dụ:
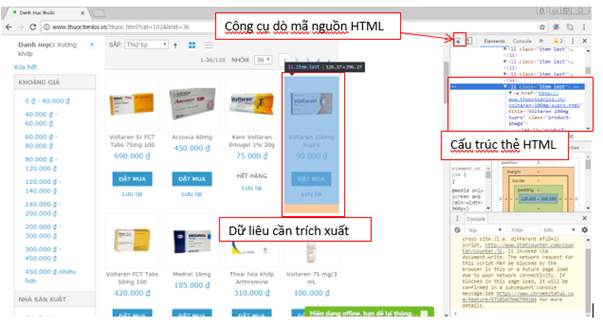
Chúng ta sẽ dùng StAX Iterator để đọc tên thẻ và giá trị thuộc tính
Khi phân tích trang web, chúng ta dễ dàng nhận thấy mỗi sản phẩm thuốc nằm trong một thẻ <li>. Tuy nhiên, thẻ <li> tồn tại ở rất nhiều vị trí. Do vậy, chúng ta sẽ dùng thuộc tính class = “item last” để phân loại thẻ <li>.

Chúng ta cũng dễ dàng nhận thấy tên thuốc nằm trong thẻ <a>. Tuy nhiên, Thẻ <a> lại nằm trong thẻ <h2>, thẻ <h2> lại nằm trong thẻ <div> và thẻ <div> lại nằm trong thẻ <li>. Qua việc phân tích này, chúng ta cần xác định 3 cờ pre conditions mới có thể biết được thẻ <a> cần tìm. Nếu quan sát kĩ, chúng ta có thể thấy trong thẻ <li> chứa sản phẩm thuốc và tên thuốc có chứa sẵn trong thuộc tính “title” của thẻ <a> đầu tiên từ trên xuống. Do vậy, chúng ta đã xác định được vị trí tên thuốc là giá trị thuộc tính “title” của thẻ <a> trong thẻ <li>.

Tương tự, chúng ta cũng nhận thấy đường dẫn hình ảnh là giá trị của thuộc tính “src” của thẻ <img> trong thẻ <li>. Từ đây, chúng ta có thể sử dụng bộ parse StAX kết hợp một số cờ boolean để lấy được dữ liệu cần tìm là tên thuốc và hình ảnh.
Lưu ý: bộ parse StAX chỉ cung cấp tên thẻ và loại thẻ đang trỏ tới hiện tại chứ không cung cấp vị trí của thẻ so với thẻ khác. Do đó, chúng ta nên sử dụng một số cờ boolean đóng vai trò như cột mốc để xác định bộ parse đang đọc nhằm xác định vị trí thẻ theo cấp độ lồng ghép trong tài liệu (chi tiết sẽ được thể hiện rõ trong source code bên dưới).
Bước 2: Khởi tạo Java Class để tổ chức cấu trúc dữ liệu sử dụng JAXB
Tại bước này, quí vị vui long tham khảo bài http://www.kieutrongkhanh.net/2016/10/jaxb-chuyen-oi-xml-schema-hay-dtd-tro.html về cách thức sử dụng JAXB.
Chúng ta tạo schema có cấu trúc như sau

Thực hiện phát sinh các JAXB class từ schema nêu trên:

Cấu trúc project sau khi phát sinh:

Bước 3: Cấu hình StAX parser để phân tích dữ liệu
Đầu tiên, chúng ta thực hiện tải tài liệu HTML cần xử lý sử dụng API được cung cấp bởi thư viện java.net như sau

Tài liệu HTML sẽ được lưu trữ ở đường dẫn thư mục “filePath”.
Chúng ta sẽ dùng StAX parser để trích xuất dữ liệu từ tài liệu này.
Tài liệu HTML bản chất là một XML không well-form. Do đó, chúng ta cần cầu hình bộ parser bỏ qua các lỗi này trong quá trình xử lý như sau

Tiếp theo, chúng ta cần cờ boolean để xác định bộ parse đang đọc trong thẻ <li> có thuộc tính class = “item last” để xác định thẻ <li>
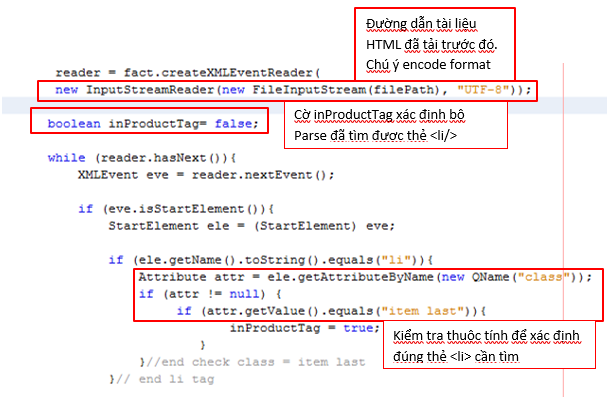
TIếp theo, chúng ta tìm tên thuốc và hình ảnh theo các bước đã phân tích từ bước 1:

Tiếp đến, chúng ta thực hiện lưu dữ liệu vào JAXB Object ngay khi lấy được dữ liệu:

Để đảm bảo tính đúng đắn dữ liệu, ta thực hiện chuyển dữ liệu thành tài liệu XML để validate trước khi sử dụng.

Tiếp theo ta sử dụng XML Validator để kiểm tra dữ liệu. Ở cách thông thường ta hay dùng java code để kiểm tra validation, chẳng hạn số điện thoại gồm 10 -12 số, hoặc matching với Regular Expression số điện thoại Việt Nam, hay tên không chứa ký tự đặc biệt,… Thay vào đó ta tận dụng lợi điểm của XML schema để validate những yếu tố trên.

Chúc mừng bạn đã hoàn tất về việc sử dụng StAX parser trong việc trích xuất dữ liệu từ tài liệu HTML. Chúng tôi hy vọng bạn sẽ sử dụng dữ liệu được xử lý vào những mục đích hữu dụng và hợp pháp.
Rất mong đóng góp chân thành của quí vị về nội
dung bài viết này.
Bài rõ ràng và có giải thích chi tiết, nhưng nên bổ sung thêm:
Trả lờiXóa1/ Nên screenshot thêm phần import thư viện để tránh gây confused giữa các thư viện được sử dụng.
2/ Nên screenshot cả tên file đang được code, để giúp người đọc xác định được vị trí function.