Sử dụng mô hình “Máy trạng thái” (State-machine) kết hợp đọc schema để khôi phục tài liệu XML bị lỗi
Tác giả: Bạch Minh Nam
Mục đích: Chủ đề của bài viết này hướng dẫn cách hiện thực bộ đọc cú pháp XML bằng sơ đồ máy trạng thái (dựa trên những khái niệm đã được trình bày trong bài viết trước đó, tham khảo tại địa chỉ http://www.kieutrongkhanh.net/2018/12/su-dung-mo-hinh-may-trang-thai-state.html), kết hợp phân tích schema để khôi phục lại tài liệu XML bị các lỗi liên quan đến thiếu thẻ đóng/mở.
Ví dụ, cho tài liệu XML lỗi như sau

Kết quả xử lý sau khi khôi phục sẽ là

Yêu cầu kiến thức cơ bản:
- Nắm rõ những phương pháp cơ bản của lập trình hướng đối tượng bằng ngôn ngữ Java
- Nắm rõ khái niệm về XML và cách viết một tài liệu chuẩn well-form (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-inh-nghia-cach-viet.html)
- Nắm rõ cú pháp và cách viết schema cho tài liệu XML (thao khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-schema-inh-nghia-cach.html)
- Hiểu được khái niệm máy trạng thái và cách thức lập trình dựa vào sơ đồ trạng thái (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2018/12/su-dung-mo-hinh-may-trang-thai-state.html)
Công nghệ sử dụng:
- IDE: Netbeans 7.4 hoặc Netbeans 8.x hoặc IntelliJ IDEA
- JDK: JDK 7 hoặc JDK 8
- Library: Apache Xerces2 Java (tải về tại địa chỉ http://mirror.downloadvn.com/apache//xerces/j/source/Xerces-J-src.2.12.0-xml-schema-1.1.zip hay một nơi lưu trữ mà quí vị có thể tìm kiếm trên internet, giải nén và copy 2 file xml-apis.jar và xercesImpl.jar thêm vào thư viện project)
I. Đặt vấn đề
Các bộ XML Parser như DOM, StAX, SAX không có khả năng thực hiện well-formed và chỉnh sửa các lỗi cú pháp. Nếu gặp phải các lỗi như thiếu thẻ đóng/mở, bộ parser sẽ dừng và gây ra lỗi chương trình, khiến việc khai thác dữ liệu bị gián đoạn.
Vì những hạn chế đó, cần có một cơ chế để đọc tài liệu XML theo các thành phần cơ bản nhất mà không cần quan tâm đến tính đúng sai trong cú pháp của tài liệu.
Để có thể thực hiện việc validation, mỗi tài liệu XML đều cần đến file schema của nó. Nếu có thể đọc được nội dung của file schema, chúng ta sẽ biết được quy luật của các thẻ XML và tận dụng để khôi phục lại tài liệu XML như ban đầu.
II. Ý tưởng:
- Để giải quyết việc đọc cú pháp của XML, chúng ta sẽ sử dụng mô hình “máy trạng thái hữu hạn” (finite-state machine modelling) cho việc quản lý biến trạng thái. Giải pháp này đã được đề cập trong bài viết trước đó (tham khảo tại địa chỉ http://www.kieutrongkhanh.net/2018/12/su-dung-mo-hinh-may-trang-thai-state.html)
- Để thực hiện việc đọc hiểu tài liệu schema, chúng ta sử dụng bộ thư viện Xerces2 Java của Apache.
- Để thực hiện viện khôi phục tài liệu XML, thay vì tiếp cận theo hướng “thử và sai” (gặp lỗi nào sửa lỗi đó) – một hướng tiếp cận đơn giản nhưng thiếu linh hoạt và tốn kém vì phải xét nhiều trường hợp, chúng ta sẽ tiếp cận theo một hướng khác: chúng ta sẽ tìm cách trích xuất dữ liệu từ tài liệu bị lỗi, càng triệt để càng tốt, sau đó đổ dữ liệu đã khai thác vào khuôn mẫu schema đã cho ban đầu để tạo ra một tài liệu XML mới và hoàn toàn validated (“bình mới rượu cũ”).

III. Sử dụng thư viện Apache Xerces2 Java để parse nội dung schema:
Nguồn tham khảo:
http://xerces.apache.org/xerces2-j/ - website chính thức của Xerces2 Java API,
http://xerces.apache.org/xerces2-j/javadocs/xs/index.html - javadoc của Xerces2 API dành cho schema,
http://xerces.apache.org/xerces2-j/faq-xs.html#faq-12 - hướng dẫn sử load schema bằng API
Chúng ta sẽ tìm hiểu cách sử dụng bộ thư viện Xercer2 này để đọc nội dung file schema.
Cấu trúc của các package trong project như sau:
- Package template chứa khuôn mẫu schema, bao gồm Element (các thẻ), Attribute (các thuộc tính) và SchemaEngine để parse schema
- Package data chứa ElementData là một wrapper của Element, có chứa dữ liệu thật sự của tài liệu XML bên trong.

- Class Element:
Đầu tiên, khai báo các constant của class. Như đã biết, các element trong XML có thể được chia làm 4 loại complex type: empty, text-only, element-only, mixed. Để đơn giản vấn đề, chúng ta xem simple type là một dạng text-only. Trong số đó, các element-only lại được chia làm 3 loại indicator tương ứng: all, sequence, choice.
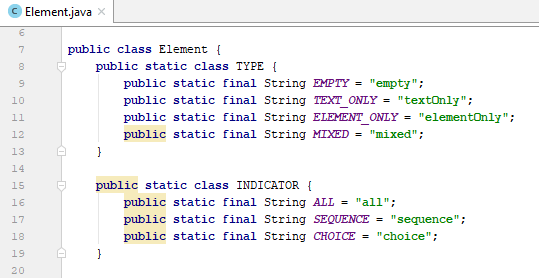
Tiếp theo, khai báo và quy ước các biến

- type: loại element, là một trong các field của Element.TYPE
- name: tên element
- max: maxOccurs của element
- min: minOccurs của element
- unbounded: element có được phép xuất hiện vô hạn lần hay không
- attributes: chứa các attribute được khai báo trong element
- childElements: chứa các element con trực tiếp, nếu đây là element-only.
- innerType: xác định loại indicator của element này, là một trong những field của Element.INDICATOR. Mặc định giá trị khởi tạo là sequence.
- parent: chứa element cha trực tiếp của nó nếu có
Tạo getter/setter tương ứng, và constructor để khởi tạo các biến thành phần.

Sau đó, chúng ta hiện thực một số phương thức cho class Element.
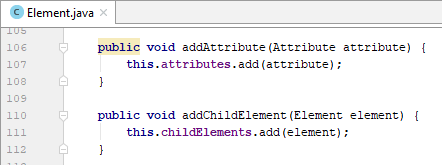

- getChildElement(String name): lấy ra element con trực tiếp có tên trùng với name
- getDescendantElement(String name): lấy ra element con trực tiếp/gián tiếp có tên trùng với name.

- containsDescendant(String tagName): kiểm tra xem element có chứa element con trực tiếp/gián tiếp có tên trùng với tagName hay không
- containsChild(String tagName): kiểm tra xem có chứa thẻ con trực tiếp có tên trùng với tagName hay không
- containParent(String tagName): kiểm tra xem có chứa thẻ cha trực tiếp hoặc gián tiếp, có tên trùng với tagName hay không.
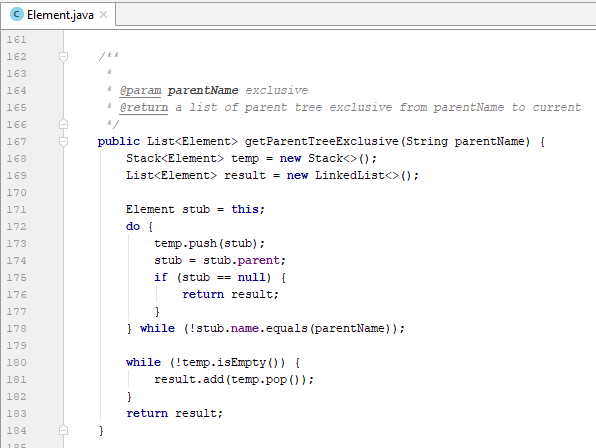
- getParentTreeExclusive(String parentName): trả về một list tất cả các element cha của element hiện tại theo thứ tự cây phả hệ, bắt đầu (nhưng ngoại trừ) từ parentName, kết thúc tại element hiện tại.
- Ví dụ: Cho tài liệu XML như hình dưới, khi đó phương thức getParentTreeExclusive của element title với tham số là “books” sẽ trả về kết quả như sau:

- Class Attribute:
Chứa thông tin về 1 attribute của 1 element, bao gồm các field như hình dưới, thêm các getter/setter tương ứng.

- Class SchemaEngine:
Đây là bộ parser giúp chúng ta đọc nội dung của file schema và lưu cấu trúc đó được dưới dạng các Element và Attribute đã được mô tả như ở phần trên.
Đầu tiên khai báo các constant. Chúng ta tạo biến mapping giữa constant dạng integer COMPOSITOR của Xerces API và constant dạng String INDICATOR quy ước trong Element.

- Đoạn code nằm bên trong khối lệnh static sẽ chạy để khởi tạo giá trị cho những biến static của class
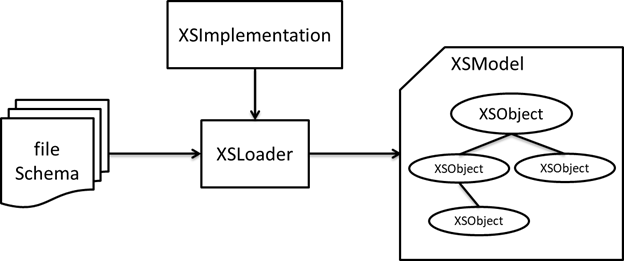
Mô hình hoạt động của Xerces2 Java API như sau:
|
Interface |
Description |
|
XSImplementation |
Dùng để khởi tạo instance XSLoader |
|
XSLoader |
Chứa method dùng để load tài liệu schema vào bộ nhớ và parse thành XSModel |
|
XSModel |
Là interface trỏ đến vùng nhớ có chứa nội dung schema đã được parse |
|
XSObject |
Là interface đại diện cho bất kì một loại component nào của schema, có thể là một element hoặc một attribute... |

Trước tiên, chúng ta thực hiện hàm load schema từ một đường dẫn bất kì vào bộ nhớ và lưu thành XSModel
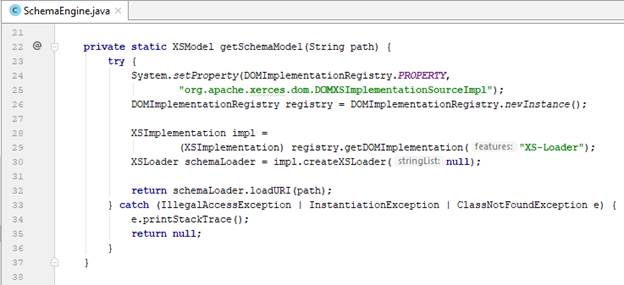
Sau đó thực hiện duyệt đệ quy các thành phần có trong XSModel để tạo ra các object Element phản ánh cấu trúc của schema đó. Element cuối cùng được trả về chính là root node của tài liệu XML.
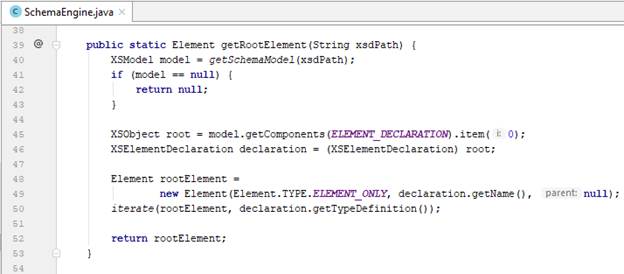
- Thông thường, mỗi schema sẽ bao gồm nhiều type definition và chỉ một khai báo element ở scope global của tài liệu. Khai báo element đó chính là root element của tài liệu XML sau này. Do đó, chúng ta lấy ra XSObject đầu tiên thuộc loại ELEMENT_DECLARATION và tạo thành root element.
- Mỗi một khai báo element sẽ chứa thông tin về element type, được lưu trong XSTypeDefinition. Chúng ta thực hiện duyệt kiểm tra chi tiết hơn về các type definition đó.

- Element có 2 loại, simple type và complex type. Tiếp tục thực hiện duyệt chi tiết hơn với mỗi loại.
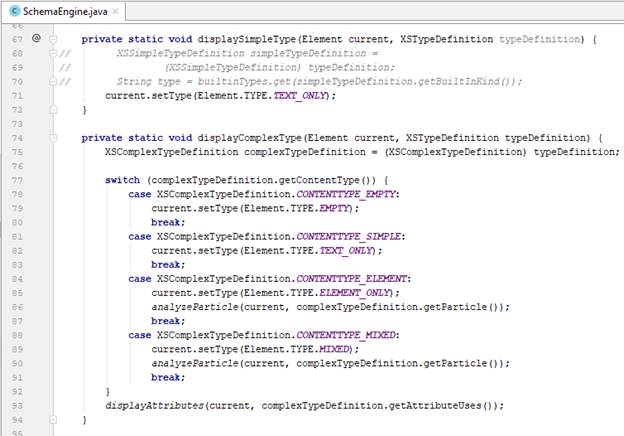
- Trong trường hợp đó là simple type, chúng ta xem xét nó như text-only là một dạng complex type, để giảm bớt trường hợp xử lý. Tuy nhiên, quý vị cũng có thể thực hiện kiểm tra chi tiết hơn bằng cách lấy ra thông tin về loại built-in type của simple type đó, để cải tiến việc khôi phục tài liệu XML sau này, khi có thể phân biệt được giữa kiểu String và kiểu số numerical.
- Trong trường hợp complex type, chúng ta có 4 trường hợp con ứng với 4 loại complex type: empty, text-only, element-only và mixed. Sau đó kiểm tra và lấy thông tin về các attribute.
- Với element-only và mixed, chúng ta thực hiện duyệt chi tiết từng element con của nó thông qua việc lấy ra các XSParticle.
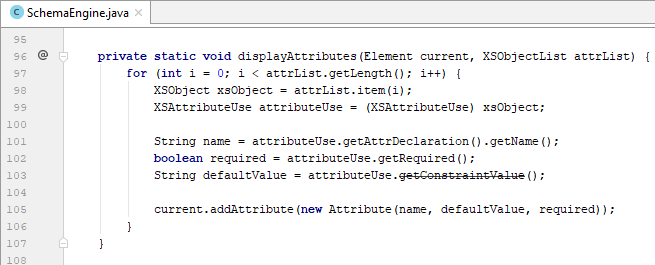

- Việc trích xuất thông tin của các element con có một chút sự phức tạp hơn so với các component khác. Đầu tiên kiểm tra xem particle này có phải là một MODEL_GROUP hay không. Nếu có, thực hiện ép kiểu về XSModelGroup và lấy ra thông tin về loại indicator (all, sequence hay choice?), sau đó duyệt từng particle con, ép kiểu về XSElementDeclaration và lặp lại quá trình như đã làm với root element.
- Tuy nhiên với mỗi element con, chúng ta còn lấy ra thông tin về minOccurs, maxOccurs và maxOccursUnbounded.
- Vì quá trình này là đệ quy nên mỗi hàm đều có tham số bắt buộc là Element hiện tại đang được trích xuất dữ liệu.
Chúng ta đã hoàn thành xong việc đọc và phân tích schema thành các element và attribute.
- Class ElementData:
Tiếp theo, chúng ta tiếp tục tạo class ElementData. Đây có thể được xem là một wrapper của Element, lấy Element làm khuôn mẫu, để chứa dữ liệu thật sự về tài liệu XML.

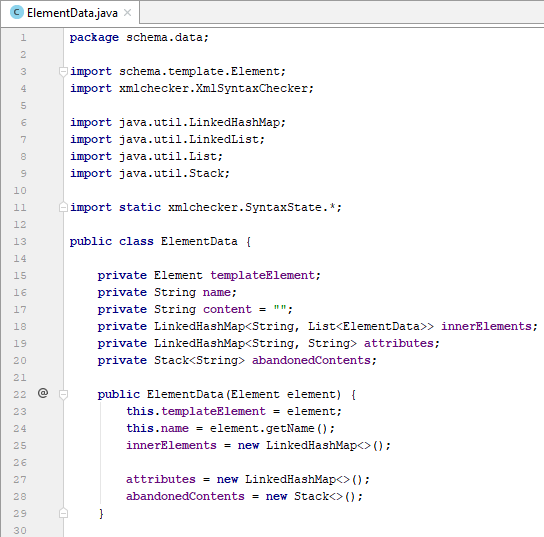
- templateElement: trỏ đến đối tượng schema Element chứa thông tin về tag (element) hiện tại
- name: tên tag
- content: chứa dữ liệu của tag, nếu tag là một text-only element
- innerElements: chứa các tag con, nếu tag hiện tại là một element-only (chúng ta tạm thời bỏ qua trường hợp mixed để đơn giản vấn đề). Việc lưu trữ dưới dạng một map các list có ý nghĩa giúp quản lý tốt hơn các element con lặp lại, trong trường hợp maxOccurs của nó lớn hơn 1 hoặc maxOccurs của nó là “unbounded”.
- atributes: chứa các attribute của tag hiện tại
- abandonedContents: là một stack chứa các content tạm thời không xác định được thuộc về tag nào trong quá trình đọc.
- Thực hiện constructor với tham số là Element schema khuôn mẫu, cùng các getter/setter tương ứng.
Tiếp theo, thực hiện các hàm:

- addInnerElement: thêm một element con vào element hiện hành
- isTextOnly: kiểm tra xem nó có phải là một complex type dạng text-only hay không
- isEmptyElement: kiểm tra xem nó có phải empty tag hay không
- isElementOnly: kiểm tra xem nó có chứa các tag con hay không
Chúng ta đã hoàn tất việc đọc file schema bằng thư viện Xerces2 API và ghi thành cấu trúc Element đệ quy.
IV. Sử dụng stack để thực hiện trích xuất dữ liệu từ tài liệu XML bị lỗi:
Chúng ta sẽ tìm cách sử dụng stack để triển khai giải thuật xử lý việc đọc tài liệu XML. Có 3 trường hợp chính khi duyệt tài liệu: gặp thẻ mở, gặp thẻ đóng, và gặp content.
Lưu ý: đối tượng được lưu vào stack ở đây là ElementData, vì nó có thể chứa dữ liệu XML thực sự, chứ không phải Element vì nó chỉ chứa thông tin về cấu trúc schema.
Đầu tiên, xét trường hợp lý tưởng, là khi tài liệu XML hoàn toàn validate, chúng ta có hướng đi của giải thuật như sau:
- Gặp thẻ mở: khởi tạo một ElementData, liên kết nó với ElementData cha đã tồn tại trước đó trong đỉnh stack nếu có, sau đó bỏ vào stack.
- Khi gặp content: lưu nó vào ElementData ở đỉnh stack.
- Gặp một thẻ đóng tương ứng: lấy ra khỏi đỉnh stack ElementData đó. Như vậy, kết thúc tài liệu XML, stack rỗng, và ElementData cuối cùng được lấy ra chính là root element.

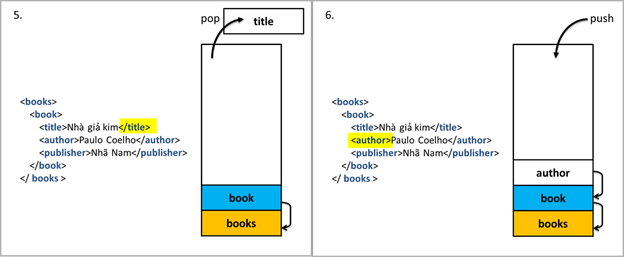
Tuy nhiên, không phải lúc nào tài liệu XML cũng được well-formed và validate sẵn. Ứng với các trường hợp tài liệu bị lỗi thiếu thẻ đóng/mở, chúng ta có những ý tưởng cơ bản như sau:
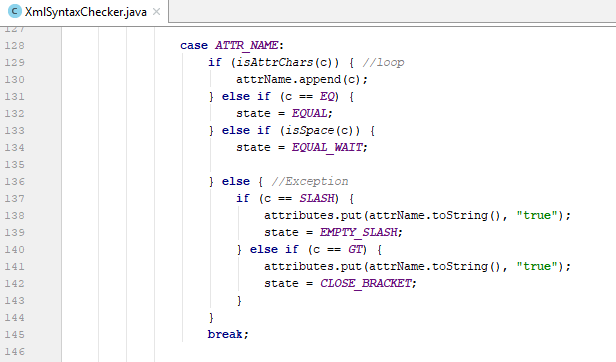
- Thẻ mở:
- Trong điều kiện tài liệu XML đã được validated, nếu gặp một thẻ mở, element ở đỉnh stack luôn luôn phải là cha trực tiếp của thẻ mở này. Như hình minh họa ở trên, các element luôn tồn tại trong stack theo đúng thứ tự “phả hệ” của nó. Do vậy, có thể coi stack là một “cây phả hệ” phản ánh chính xác mối quan hệ cha con trực tiếp giữa những element tồn tại trong đó.
- Do đó, khi gặp một thẻ mở bất kì không phải là con trực tiếp của element ở đỉnh stack, chúng ta thực hiện: liên tục lấy element ra khỏi đỉnh stack cho đến khi gặp được cha trực tiếp hoặc gián tiếp của thẻ mở ấy,
- Sau đó, nếu element hiện tại trong đỉnh stack là cha gián tiếp của thẻ mở (cha của cha), chúng ta thực hiện “điền” vào “cây phả hệ” những cha gián tiếp/trực tiếp còn thiếu, cho đến khi gặp thẻ mở hiện tại, và tiếp tục quay về quá trình đọc như bình thường.
- Tất nhiên, để biết được thứ tự “phả hệ” của các element, cần thiết phải biết được cấu trúc schema của nó, chính là vấn đề chúng ta đã đặt ra và giải quyết ở phần III vừa rồi.

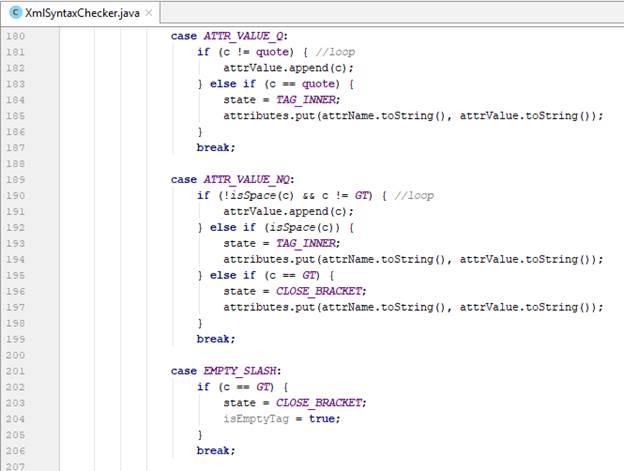
- Content:
- Dễ dàng nhận thấy, một element không nhất thiết phải có đủ cả hai thẻ đóng mở mới có thể xác định nội dung content của element đó. Chỉ cần một trong hai thẻ với nội dung ở vị trí xác định, chúng ta đã có thể biết được element đó chứa content gì.

- Trong trường hợp còn lại, khi content nằm ở vị trí không xác định, chúng ta lưu nó vào khay nhớ tạm thời của element ở đỉnh stack.

- Khay nhớ tạm thời đó sẽ là một stack, vì các content được phát hiện mới hơn sẽ có khả năng cao hơn là nội dung của các element được đọc vào tiếp theo (như trường hợp ở trên, “Paulo Coelho” được lưu ở khay nhớ tạm sẽ là content của thẻ đóng <author> tiếp theo được đọc).
- Thẻ đóng:
- Trong điều kiện XML đã validated, nếu gặp một thẻ đóng, nó phải luôn trùng tên với element ở đỉnh stack, vì thẻ đóng ấy là dùng để đóng element ở đỉnh stack.
- Nếu không, thẻ đóng ấy sẽ đóng lại một trong các element đang tồn tại trong stack (1), hoặc rất có thể là để đóng lại một element nào đó chưa từng được tạo ra (2).
- Với trường hợp (1), chúng ta chỉ cần liên tục lấy ra khỏi stack cho đến khi gặp element có thẻ đóng tương ứng mà không cần làm gì thêm. Ở đây ta dễ dàng nhận thấy, thẻ đóng chính là một trong các element cha của đỉnh stack.

- Với trường hợp (2), chúng ta thực hiện liên tục lấy ra khỏi stack cho đến khi gặp element cha trực tiếp hoặc gián tiếp của thẻ đóng hiện tại. Sau đó, thực hiện “điền” vào “cây phả hệ” những cha gián tiếp và trực tiếp còn thiếu nếu cần (tương tự như những gì đã làm với trường hợp thẻ mở), tạo mới element hiện tại, và cũng không quên lấy ra content lưu trong khay nhớ tạm đặt làm content của element mới được tạo này.

Vậy là chúng ta đã hoàn thành việc triển khai ý tưởng sử dụng stack để thu thập dữ liệu từ file XML bị lỗi.
V. Hiện thực:
Cấu trúc package khi hoàn thành như sau:

- Class FileUtils:
Đây là class dùng để đọc file text từ bên ngoài và trả về nội dung file dưới dạng String, với một method duy nhất là readTextContent(String filePath)

- Lưu ý: lúc append từng biến line, chúng ta phải append thêm một kí tự xuống dòng “\n”, vì hàm readLine đang thực hiện đọc theo từng dòng.
Tương tự với ý tưởng của bài viết trước về việc xử lý tài liệu chưa well-formed (xem tại địa chỉ http://www.kieutrongkhanh.net/2018/12/su-dung-mo-hinh-may-trang-thai-state.html), để thực hiện việc đọc nội dung XML mà không quan tâm đến tính đúng sai của nó, chúng ta sử dụng mô hình “máy trạng thái” làm máy đọc cú pháp XML. Phần hiện thực máy đọc đã được mô tả đầy đủ và chi tiết ở bài viết trước, bao gồm 2 class chính là SyntaxState lưu trữ các hằng số và các static method dùng chung, và class XmlSyntaxChecker hiện thực hàm đọc file XML.
Tuy nhiên, để đáp ứng cho mục đích ban đầu của bài viết này, có một số thay đổi trong cách hiện thực của 2 class đó, như mô tả trong phần 2 và 3 sau đây.
- Class SyntaxState:
Trong phần khai báo các hằng số dùng để làm state cho máy trạng thái, chúng ta khai báo thêm 1 state là PROCESS_INSTRUCTION, 2 hằng số kí tự là QUESTION_MARK (?) và NEW _LINE (\n)


- Ở method isNamedChar(char c), chúng ta bổ sung thêm trường hợp chấp nhận dấu hai chấm “:” để giữ nguyên những thẻ hoặc attribute có namespace.
- Ở method isSpace(char c), chúng ta bổ sung thêm trường hợp chấp nhận kí tự xuống hàng “\n” cũng được xem là một khoảng trắng.
- Class XmlSyntaxChecker:
Bên cạnh những method và field cũ, class XmlSyntaxChecker được bổ sung thêm những field và method mới, cùng 1 constructor như hình mô tả.

3.1. Tổng quan:
- Hàm setSchema nhận vào đường dẫn của tài liệu schema mô tả cấu trúc XML và thực hiện parse phân tích cấu trúc file schema đó, kết quả được lưu lại trong biến rootElement. Biến stack dùng để thực hiện việc trích xuất dữ liệu theo ý tưởng triển khai ở phần IV.
- Hàm check dùng để đọc nội dung XML tuần tự theo từng component (thẻ mở, thẻ đóng, content), thực hiện trích xuất dữ liệu lưu vào stack, và trả về kết quả là tài liệu XML đã được khôi phục đúng theo cấu trúc schema đã cho.
- Các hàm còn lại được sử dụng để bổ trợ cho hàm check.
3.2. setSchema(String path):
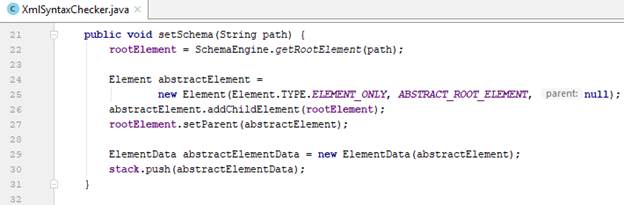
- Để đọc parse file schema và lấy ra rootElement, ta sử dùng phương thức static getRootElement(String path) của class SchemaEngine đã mô tả ở phần III.
- Để đảm bảo cho stack không bao giờ rỗng trong quá trình đọc kiểm tra tài liệu XML, chúng ta tạo ra một abstract root element khác bọc lấy root element chính đã có, và đẩy vào stack trước tiên. Trong quá trình đọc, để abstract root đó không bị lấy ra khỏi stack, chúng ta sẽ đặt một tên không hợp lệ cho nó bằng cách thêm vào các kí tự đặt biệt. Giá trị của constant ABSTRACT_ROOT_ELEMENT được mô tả trong class ElementData:

3.3. checkTagExist(String tagName):
- Dùng để kiểm tra xem một thẻ đóng/mở có thực sự tồn tại trong tài liệu XML với schema đã cho hay không

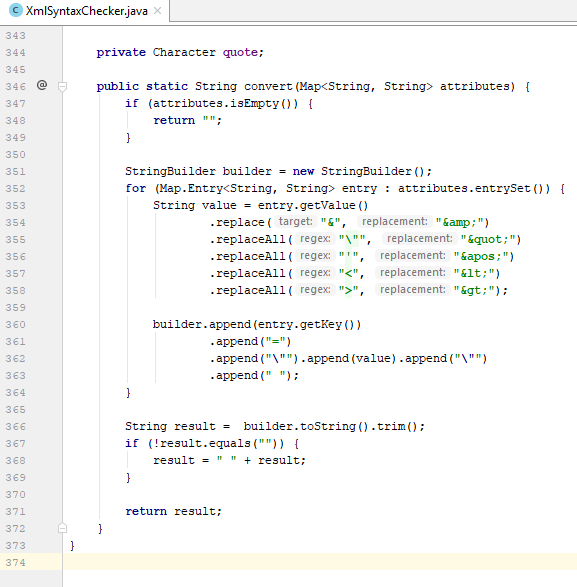
3.4. convert(Map<String, String> attributes):
- Dùng để chuyển tập attribute bao gồm các cặp key-value về dạng chuẩn XML. Như ở bài viết trước, cùng với biến quote, hàm này không có gì thay đổi
3.5. check(String src):
- Trong phần khai báo các biến cục bộ, chúng ta bỏ đi biến writer vì đã sử dụng stack thay thế. Giữ nguyên như cũ các biến còn lại.
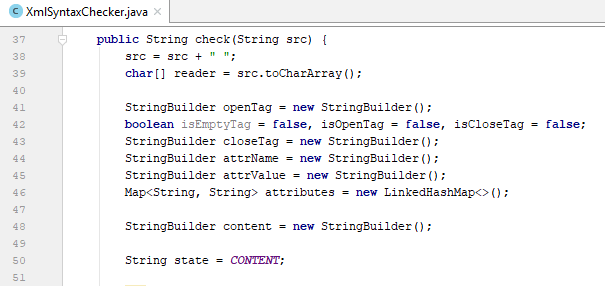
- Để máy đọc hiểu và bỏ qua các process instruction, tại state OPEN_BRACKET, chúng ta thêm trường hợp kí tự mở đầu thẻ là một dấu chấm hỏi <? >, và chuyển sang state PROCESS_INSTRUCTION. Tại state PROCESS_INSTRUCTION, mọi kí tự đều được bỏ qua cho đến khi gặp kí tự đóng thẻ “>”, máy đọc tự động chuyển lại về trạng thái CONTENT và xử lý như bình thường.



- Ngoại trừ 2 state CONTENT và CLOSE_BRACKET (nơi xác định các trường hợp content, thẻ đóng, thẻ mở) thì các state còn lại đều không thay đổi.



- Tại state CONTENT, ngay khi kết thúc việc đọc một content, chúng ta thực hiện cắt nhỏ nội dung content theo kí tự xuống dòng thành một list String. Sau đó, kiểm tra xem element tại đỉnh stack có phải là loại text-only hay không. Nếu phải, set biến String đầu tiên của list content vừa chia làm content của element đó. Sau đó, lưu list content vào khay nhớ tạm thời của element đó.

- Cách giải quyết trên sẽ giúp xử lý cho những trường hợp như hình dưới đây, khi element đầu tiên bị thiếu thẻ đóng, element thứ hai bị thiếu thẻ mở, nhưng content đọc được lần đầu lại là của cả hai element, được phân cách bởi kí tự xuống dòng.

- Tại state CLOSE_BRACKET, chúng ta có 2 trường hợp: gặp thẻ mở hoặc gặp thẻ đóng. Trong cả hai trường hợp, chúng ta kết hợp thêm điều kiện kiểm tra tên thẻ có tồn tại trong schema hay không, để loại trừ những thẻ “lạ” xuất hiện.

- Với trường hợp thẻ mở, chúng ta hiện thực như ý tưởng đã mô tả trong phần giải thuật IV. Lưu ý, không nên nhầm lẫn giữa 2 class Element và ElementData. Element là khuôn mẫu, chứa những rules về element do schema quy định. ElementData chứa dữ liệu thực sự của thẻ, bao gồm content của thẻ đó nếu là text-only, hoặc những thẻ con của nó – những ElementData con của nó, nếu là element-only. Biến templateElement chứa trong ElementData như một tham chiếu để tham khảo cấu trúc schema.

- Với trường hợp là thẻ đóng, chúng ta kiểm tra thêm một điều kiện nữa là thẻ đóng hiện tại có phải đóng root element hay không, để ngăn ngừa trường hợp tài liệu XML chưa kết thúc nhưng xuất hiện thẻ đóng root giữa chừng.

- Bởi quá trình liên tục lấy element ra khỏi stack để tìm cha trực tiếp hoặc gián tiếp của thẻ đóng, chúng ta phải lưu lại element ở đỉnh stack trong lần đầu tiên không bị mất dấu vết. Quá trình xử lý giống với những gì đã được mô tả ở phần IV.
- Bên cạnh đó, sau khi “điền cây phả hệ” cho thẻ đóng hiện tại, chúng ta lấy ra content lưu trong khay nhớ tạm (dạng stack) để làm content cho chính thẻ đóng đó.
- Sau khi kết thúc hai trường hợp, biến content được reset và chuyển state mới như bình thường. Với trường hợp gặp hai thẻ đóng dạng text-only liên tục, chúng ta thêm một kí tự rỗng vào khay nhớ tạm để ngừa việc thẻ đóng theo sau lấy nhầm content khác rỗng không phải của mình (vì thẻ đóng đó không có content).

- Sau đó kết thúc hàm check, lấy ra ElementData nằm dưới cùng stack (chính là abstrack root element) và thực hiện chuyển đổi thành chuỗi XML kèm theo dữ liệu đã thu thập.

- Chúng ta hiện thực hàm toString(String indent) của class ElementData như sau:

- Hàm toString nhận vào biến indent để các element thụt đầu dòng theo thứ tự phân cấp của nó. Hằng số INDENT_OFFSET chỉ định độ chênh lệnh khoảng trắng giữa hai cấp element (ở đây là 4 khoảng trắng)
- Đầu tiên kiểm tra xem, nếu ElementData hiện tại là abstract root, sẽ bỏ qua nó và lấy ElementData con đầu tiên để in ra kết quả.
- Tiếp theo, khởi tạo biến builder và thực hiện ghi nội dung dữ liệu có trong ElementData vào biến builder.

- Nếu là empty element, chỉ cần đơn giản ghi vào builder theo thứ tự “<tên_thẻ attributes/>”
- Ngược lại, khởi tạo 2 thẻ đóng và mở tương ứng. Nếu là text-only element, chỉ cần thêm content vào chính giữa và trả về kết quả. Nếu là element-only, chúng ta ghi vào nội dung của từng element con, nhưng phải theo thứ tự ban đầu do schema quy định (lưu trong templateElement) để dự phòng phù hợp với indicator sequence. Và nếu có một required element vắng mặt (minOccurs của nó bằng 1), chúng ta thêm vào một ElementData rỗng không có dữ liệu.
- Cách hiện thực này vẫn chưa giải quyết vấn đề số lượng element con vượt quá maxOccurs do schema quy định (có thể xử lý bằng cách tạo ra một element cha mới chứa số element con còn dư lại). Quý vị có thể tự cải tiến phương pháp hiện thực tại hàm này. (Ý tưởng có thể sửa hết việc sai cấu trúc một lần duy nhất rồi sau đó check dữ liệu với schema lần nữa)
VI. Kiểm tra kết quả:
Đầu tiên, chúng ta chuẩn bị file schema và tài liệu XML không lỗi.


Tiếp theo, chúng ta cố tình tạo lỗi cho file XML.
Thực hiện class TestChecker kiểm tra kết quả:
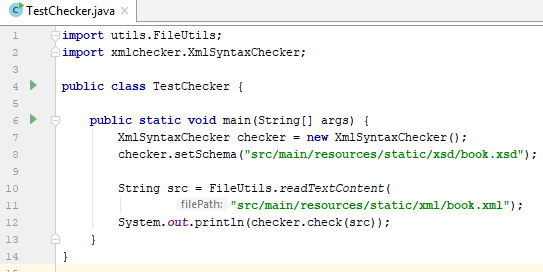
Kết quả in ra màn hình là tài liệu XML đã được khôi phục giống với nguyên bản ban đầu.
Tiếp tục thử với những trường hợp lỗi khác phức tạp hơn. File Schema:


Tài liệu XML ban đầu:

Tài liệu bị lỗi lúc sau:

Kết quả in ra màn hình sau khi chạy:

Chúc mừng quí vị đã hoàn tất việc triển khai và hiện thực bộ đọc và khôi phục tài liệu XML bị lỗi dựa trên schema của chúng.
Ở đây, chúng ta thấy rõ tầm quan trọng của kiến thức nền, về định nghĩa XML well-formed và cú pháp của schema, kết hợp kĩ thuật lập “Máy trạng thái hữu hạn”, cùng những kiến thức về cấu trúc dữ liệu đơn giản như stack, khi áp dụng linh hoạt sẽ giúp giải quyết những bài toán phức tạp.
Bên cạnh đó, khả năng đọc hiểu tài liệu javadoc và sử dụng thư viện bổ trợ cũng rất quan trọng cho sự thành công của việc giải bài toán.
Rất mong quí vị góp ý về nội dung bài viết này.
Không có nhận xét nào:
Đăng nhận xét