Sử dụng mô hình “Máy trạng thái” (State-machine) để biến đổi nội dung HTML thành chuẩn XML well-formed mà không cần hardcode
Tác giả: Bạch Minh Nam
Mục đích: Chủ đề của bài viết này hướng dẫn cách hiện thực bộ tiền xử lý nội dung HTML thành chuẩn XML well-formed, trước khi đưa vào các bộ parser để đọc XML như DOM, StAX hoặc SAX với mục tiêu trích xuất dữ liệu.
Yêu cầu kiến thức cơ bản:
- Nắm rõ những phương pháp cơ bản của lập trình hướng đối tượng bằng ngôn ngữ Java
- Nắm rõ khái niệm về XML và cách viết một tài liệu chuẩn well-form (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-inh-nghia-cach-viet.html)
- Nắm rõ cú pháp của HTML/HTML5 và hiểu được sự khác biệt giữa XML và HTML (thao khảo tại W3Schools https://www.w3schools.com/html/html5_syntax.asp)
Công nghệ sử dụng:
- IDE: Netbeans 7.4 hoặc Netbeans 8.x
- JDK: JDK 7 hoặc JDK 8
I. Đặt vấn đề:
Việc khai thác và trích xuất dữ liệu từ các website trên internet là một nhu cầu phổ biến hiện nay. Tuy nhiên, ở định dạng HTML, dữ liệu của những website đó phần lớn là tài liệu XML không được well-formed và không tương thích với các bộ parser dành cho XML.
- Một số lỗi khiến tài liệu XML không được well-formed lại là cú pháp hoàn toàn hợp lệ đối với HTML, có thể được kể đến như sau:
- Attribute không chứa value:
<option selected>Audi</option>
- Attribute có value không bọc trong dấu nháy:
<input type=text name=“username”/>
- Attribute viết liền nhau không có khoảng trắng để phân cách:
<div class=“panel”data-type=“numerical”/>
- HTML còn chấp nhận các thẻ gọi là empty-elements (tham khảo tại https://developer.mozilla.org/en-US/docs/Glossary/Empty_element), là những thẻ không chứa thẻ con bên trong, và không cần thực hiện thao tác đóng thẻ ở cuối thẻ. Ví dụ, cách viết <br> là hoàn toàn hợp lệ trong HTML. Do đó nó được xem như một lỗi cú pháp trong tài liệu XML (có thẻ mở mà không có thẻ đóng).
- Ngoài ra, tài liệu HTML còn chứa thẻ <script> cho phép chứa mã javascript trong đó có những kí tự sẽ gây lỗi cho tài liệu XML. Ví dụ như câu lệnh so sánh if (count < 1)... trong đó có kí tự “<” là một entity được định nghĩa trong XML, khi viết trực tiếp sẽ gây nhầm lẫn với dấu hiệu bắt đầu thẻ mở.
- HTML cũng định nghĩa các tham chiếu entity khác với XML có thể gây lỗi, phổ biến nhất là thay thế cho khoảng trắng.
- HTML là ngôn ngữ không phân biệt chữ hoa và chữ thường (case insensitivity), ví dụ, cách viết <Div></dIV> là hoàn toàn hợp lệ. Trong khi đó, XML lại là ngôn ngữ case sensitive – có phân biệt chữ hoa chữ thường, nên cách viết như trên sẽ không hợp lệ, gây lỗi thẻ mở mà không có thẻ đóng.
- Và đôi khi, do lỗi lập trình, thay vì đóng đúng thẻ mở, tài liệu lấy về lại đóng nhầm thẻ khác. Ví dụ dưới đây là một đoạn mã được cắt từ website bán sách Pibook https://pibook.vn/sap-phat-hanh, trong đó ta thấy thẻ li được mở nhưng lại đóng bằng thẻ h3

Các bộ XML Parser như DOM, StAX, SAX không có khả năng thực hiện well-formed và chỉnh sửa các lỗi cú pháp. Nếu gặp phải các lỗi cú pháp trên, đa số các bộ parser sẽ dừng và gây ra lỗi chương trình hay phải thực hiện điều chỉnh trong code như với StAX, khiến việc khai thác dữ liệu bị gián đoạn.
Do đó, trước khi đưa vào các bộ XML Parser, tài liệu HTML thô cần được xử lý để loại bỏ những lỗi cú pháp và trở nên well-formed.
II. Ý tưởng:
- Chúng ta sẽ tiến hành đọc toàn bộ tài liệu HTML theo cú pháp của chúng, lưu các element và các attribute tìm thấy vào các biến tạm, và sau khi kết thúc một thẻ bất kì, ta sẽ tiến hành ghi lại các element và attribute đó vào file output với đúng syntax của XML.
- Để giải quyết việc đọc cú pháp của HTML, chúng ta sẽ sử dụng mô hình “máy trạng thái hữu hạn” (finite-state machine modelling) cho việc quản lý biến trạng thái. “Máy trạng thái hữu hạn” là một cỗ máy có nhiều trạng thái (state – được mô tả bằng tính từ) khác nhau. Tuy nhiên, tại một thời điểm, máy chỉ ở trong một trạng thái nhất định. Khi có một biến cố (event – được mô tả bằng động từ) xảy ra, bằng những dữ liệu đã được lập trình sẵn, máy sẽ chuyển từ trạng thái hiện tại sang trạng thái mới tương ứng với sự kiện mà nó đón nhận.

- “Máy trạng thái” có thể là bất cứ đối tượng nào có một cơ chế hoạt động ổn định. Ở ví dụ trên là hình minh họa cho “máy trạng thái” của một cách cửa: từ trạng thái “mở”, khi có sự kiện “đóng cửa” xảy ra, cửa sẽ chuyển sang trạng thái “đóng” và ngược lại (tham khảo tại https://en.wikipedia.org/wiki/Finite-state_machine, https://en.wikipedia.org/wiki/Automata-based_programming)
- Trong bài viết này, đối tượng áp dụng “máy trạng thái” sẽ là bộ đọc cú pháp của tài liệu HTML. Chúng ta sẽ chia cú pháp của một tài liệu HTML thành các trạng thái (states) khác nhau – mỗi khi gặp một kí tự nhất định, bộ đọc sẽ chuyển từ state này sang state kia, nhờ đó mà nó biết được vị trí của con trỏ đang ở đâu trong tài liệu HTML, và tiến hành ghi nhận các element và attribute xử lý. Ưu điểm lớn nhất của cách xử lý theo cơ chế này, chính là việc chỉ cần quản lý một biến trạng thái duy nhất, thay vì sử dụng phối hợp nhiều loại cờ (flags) để đánh dấu theo lẽ thông thường.
- Ngoài ra, để giải quyết việc thiếu thẻ đóng/mở, chúng ta sẽ kết hợp sử dụng ngăn xếp (stack) để xử lý vấn đề này.
III. Sử dụng stack để thêm thẻ bị thiếu vào tài liệu XML
Trước khi bước vào vấn đề chính, chúng ta sẽ thảo luận một hướng tiếp cận bằng stack để giải quyết 2 trường hợp lỗi well-formed XML: thiếu thẻ đóng và thiếu thẻ mở.
- Trường hợp 1: tài liệu HTML well-formed, có đầy đủ các cặp thẻ đóng mở. Cách tiếp cận xử lý
o Mỗi lần đọc đến một thẻ mở, chúng ta thêm tên thẻ vào stack. Mỗi lần đọc đến một thẻ đóng, chúng ta chỉ cần kiểm tra thẻ đóng ấy có giống với thẻ ở đỉnh stack hay không.
o Ở trường hợp tài liệu đã well-formed, tên thẻ đóng luôn luôn trùng khớp với tên thẻ ở đỉnh stack (hình 4, hình 9 và hình 10). Với trường hợp này, chúng ta chỉ cần lấy tên thẻ ra khỏi đỉnh stack, ghi vào biến output writer dưới dạng thẻ đóng. Kết thúc quá trình, stack luôn rỗng, nghĩa là luôn tồn tại đầy đủ các cặp thẻ đóng và mở.


- Trường hợp 2: tài liệu thiếu thẻ đóng
o Khi đó, tên thẻ đóng hiện tại sẽ khác với thẻ ở đỉnh stack (hình 8 bên dưới). Chúng ta thực hiện vòng lặp, liên tục lấy ra khỏi đỉnh stack và ghi vào dưới dạng thẻ đóng ở biến đầu ra writer, cho đến khi tên thẻ đóng hiện tại trùng với tên đỉnh stack.
o Kết thúc quá trình, stack rỗng, chúng ta thu được tài liệu XML đã well-formed với đầy đủ các cặp thẻ đóng và mở.
o Với các xử lý nêu trên, tài liệu đã well-formed mặc dù thứ tự đóng mở không khớp, nhưng xét ở khía cạnh khai thác dữ liệu, chúng ta vẫn đạt được mục tiêu cuối cùng là khai thác trích xuất dữ liệu thành công. Ở một mức độ nào đó, hướng tiếp cận này vẫn được chấp nhận. Với ví dụ bên dưới, chúng ta sử dụng câu query XPath title/text() cho tài liệu mẫu, sau khi qui trình well-formed (hình 12) thực hiện, kết quả xử lý vẫn cho ra việc lấy dữ liệu xử lý mong đợi là “Nhà giả kim”.
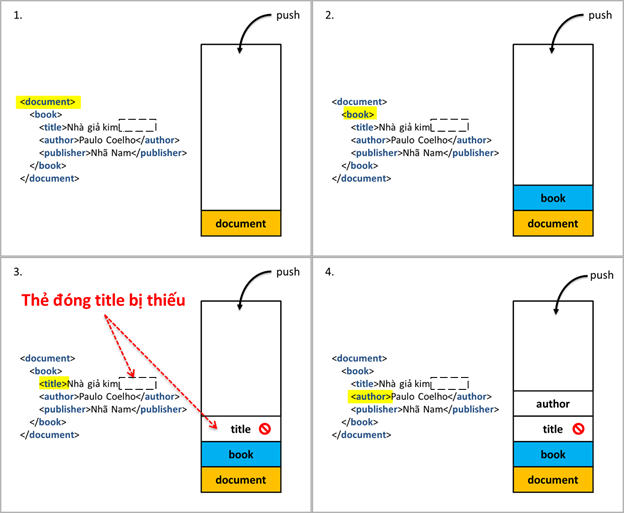


- Trường hợp 3: tài liệu thiếu thẻ mở
o Ở trường hợp này, ta có 2 trường hợp con nhỏ hơn:
1. Tài liệu đóng nhầm thẻ mở, ví dụ <li>Category</h3>
2. Tài liệu dư thẻ đóng, ví dụ <li>Category</h3></li>
o Một cách cảm tính, chúng ta dễ dàng nhận thấy, thẻ h3 ở cả hai trường hợp đều không tồn tại trong stack. Thật vậy, nếu thẻ h3 có trong stack, nghĩa là chúng ta đã duyệt qua thẻ mở của nó, khi đó h3 sẽ tồn tại thành một cặp đóng và mở đầy đủ, và không gây ra lỗi well-formed như thế này.
o Để giải quyết cả hai trường hợp, trước tiên chúng ta cần kiểm tra xem thẻ đóng hiện tại có tồn tại bên trong stack chưa. Nếu thẻ đóng hiện tại không tồn tại bên trong stack, ta bỏ qua thẻ đó và không ghi nhận vào biến đầu ra writer.
o Với trường hợp dư thẻ đóng, việc bỏ qua thẻ đóng bị dư hoàn toàn đúng đắn. Với trường hợp đóng nhầm thẻ mở, tài liệu lúc này sẽ ở trạng thái “thiếu thẻ đóng”, và quay về cách xử lý trong trường hợp thiếu thẻ đóng như đã thảo luận ở phần trên.
o Ở một số trường hợp nhất định, hướng tiếp cận này sẽ gây mất mát dữ liệu bán phần. Xét trường hợp dưới đây, sau khi xử lý well-formed, cặp thẻ <author> đã bị loại bỏ và phần thông tin chứa trong <author> cũng không thể trích xuất được theo cách thông thường:

IV. Một số khái niệm cơ bản về kĩ thuật lập trình “máy trạng thái”:
- Các kí hiệu quy ước trong sơ đồ máy trạng thái:
Ø Khung tròn (hoặc khung chữ nhật) tượng trưng cho state (trạng thái). Toàn bộ các state là hoàn toàn khác nhau.

Ø Mũi tên tượng trưng cho transition (chuyển từ trạng thái này sang trạng thái kia)

Ø Bên trên mỗi transition có các event / transition condition (điều kiện để từ trạng thái hiện tại chuyển sang trạng thái tiếp theo). Giữa hai state A và B, theo một chiều (ví dụ từ A đến B), chỉ có một transition duy nhất nối hai state đó.

- Để chuyển đổi từ sơ đồ máy trạng thái sang code tương ứng, chúng ta có những quy ước sau đây:
Ø Toàn bộ các state trong sơ đồ được lưu trữ dưới dạng constant string. Thay vì sử dụng trực tiếp giá trị string dạng literal (sẽ gây sai sót nếu ta gõ sai tên state), cách này giúp chúng ta tránh được lỗi, vì IDE sẽ thông báo nếu chúng ta gọi đến một state không tồn tại trong chương trình.
Ø Sử dụng một biến duy nhất để lưu trữ trạng thái của chương trình (dưới dạng String), và sử dụng cấu trúc switch...case để quản lý tất cả các trường hợp của biến trạng thái. (Tính năng switch...case dành cho biến kiểu String chỉ khả dụng với JDK 7 trở lên)
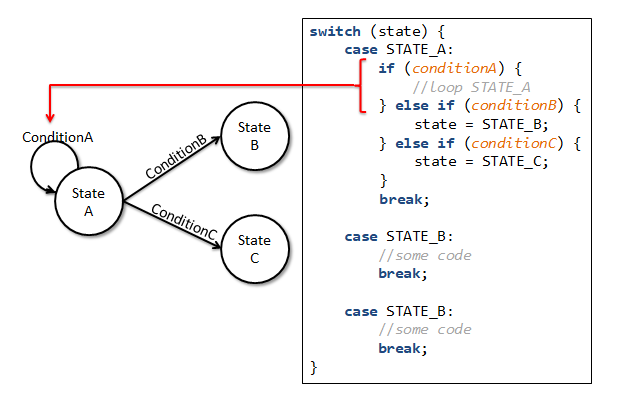
Ø Một state có thể chuyển sang nhiều state khác nhau. Khi đó, cấu trúc if...else được áp dụng cho từng transition khác nhau để đánh giá sự chuyển trạng thái. Chúng ta có sơ đồ máy trạng thái và code hiện thực tương ứng như sau:

Ø Một state có thể tự chuyển đến chính nó (loop state). Khi đó, trong khối lệnh if của điều kiện, biến state sẽ không thay đổi giá trị.
V. Triển khai ý tưởng:
Trong bài viết này, bài toán chúng ta cần giải quyết chính chính là cách hiện thực máy trạng thái để đọc hiểu cú pháp của định dạng HTML.
- Xác định event/condition: Để đọc cú pháp của nội dung HTML, chúng ta sẽ đọc từng kí tự trong chuỗi văn bản, đọc tuần tự từ trái sang phải – từ trên xuống dưới. Do đó, máy đọc sẽ triển khai một vòng lặp để lần lượt đọc hết ra từng kí tự. Nội dung của mỗi kí tự sẽ là một event kích hoạt máy đọc chuyển từ trạng thái này sang trạng thái khác.
- Xác định state:
- Theo định nghĩa cú pháp của XML, tài liệu XML bao gồm 2 thành phần chủ yếu: Markup Tags (thẻ) và Character Data (dữ liệu). Markup Tags bao gồm nhiều loại (DOCTYPE declaration, processing instruction, comment, entity reference...).
- Tuy nhiên, đối với HTML, những thẻ thực sự mang giá trị dữ liệu để phục vụ cho mục đích khai thác chỉ bao gồm 3 loại thẻ: thẻ mở/đóng thông thường, và thẻ rỗng. Thẻ rỗng có thể coi như là một loại thẻ mở, với kí tự “/” theo sau làm thẻ đóng. Do đó, các đối tượng cú pháp mà ta tập trung xử lý bao gồm: thẻ mở <openTag> hoặc <openTag/>, thẻ đóng </closeTag>, và nội dung còn lại nằm bên ngoài thẻ (character data).
- Chúng ta thực hiện định nghĩa các state cụ thể như sau:

- Giải thích:
o openBracket: trạng thái ngay sau khi gặp kí tự “<” – báo hiệu bắt đầu một thẻ mở/đóng
o openTagName: báo hiệu đang gặp tên thẻ mở
o emptySlash: báo hiệu đây là thẻ rỗng
o closeBracket: trạng thái ngay sau khi gặp kí tự “>” – báo hiệu kết thúc một thẻ mở/đóng
o closeTagSlash: báo hiệu bắt đầu thẻ đóng
o closeTagName: báo hiệu đang gặp tên thẻ đóng
- Bên trong thẻ mở có các attribute, chúng ta thực hiện thêm các state khác như sau:


- Giải thích:
o tagInner: gặp khoảng trắng – báo hiệu bắt đầu bước vào bên trong thẻ mở để ghi nhận attribute
o attrName: bắt đầu ghi nhận tên attribute
o equalWait: gặp khoảng trắng khi đang đọc tên attribute – kết thúc việc ghi nhận tên attribute
o equal: gặp kí tự “=”,chuyển sang trạng thái chờ đợi ghi nhận giá trị của attribute, theo sau có thể có 1 hoặc nhiều khoảng trắng
o attrValueQ: gặp dấu nháy (nháy đơn hoặc nháy kép) – bắt đầu ghi nhận value cho attribute name hiện tại
o attrValueNQ: gặp một kí tự bất kì (không phải khoảng trắng và không phải kí tự kết thúc thẻ “>”) – bắt đầu ghi nhận value cho attribute name hiện tại
- Khái quát hơn, chúng ta có thể mô tả cú pháp của 2 loại thẻ mở và thẻ đóng bằng sơ đồ sau:
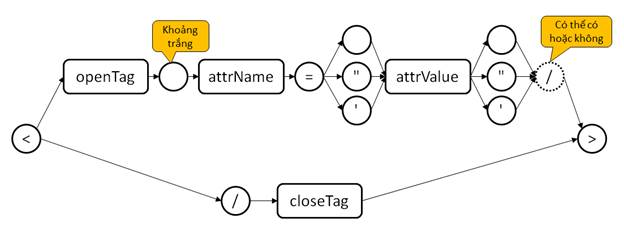
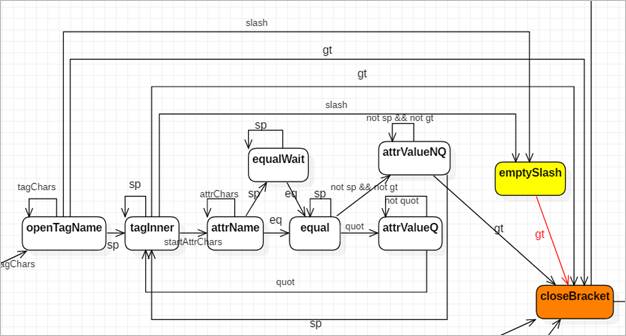
- Tuy nhiên, trạng thái (state) của máy đọc phải được mô tả bằng string. Chúng ta chuyển đổi sơ đồ trên thành sơ đồ máy trạng thái như sau:

Sơ đồ 1 (sơ đồ máy đọc cú pháp của HTML)
- Máy đọc cú pháp đọc ra từng kí tự một trong chuỗi HTML đầu vào. Mỗi kí tự là một event kích hoạt máy đọc chuyển từ state hiện tại sang state mới. Theo mô tả của sơ đồ, ta có các event sau:
o lt: kí tự đang đọc là kí tự “<” less than
o gt: kí tự đang đọc là kí tự “>” greater than
o slash: gặp kí tự “/” slash
o sp: gặp khoảng trắng space
o eq: gặp kí tự “=” equal
o quot: gặp dấu nháy (nháy đơn hoặc nháy kép) quotation
o tagChars: kí tự đang đọc thuộc tập hợp kí tự cho phép của tên tag, bao gồm chữ cái, chữ số hoặc dấu gạch dưới
o startTagChars: kí tự bắt đầu tên element (tên của tag cho phép bắt đầu bằng chữ cái hoặc bằng kí tự “:” nhưng không cho phép bắt đầu bằng số)
o attrChars: tên attribute, tương tự tagChars
o startAttrChars: kí tự bắt đầu của tên attribute, tương tự như startTagChars
- Ngoài ra còn có 2 state mới được thêm vào, đó là content (character data) và waitEndTagClose (báo hiệu kết thúc tên thẻ đóng, đợi kí tự “>” kết thúc thẻ đóng)
VI. Các bước hiện thực:
- Class SyntaxState:
- Đầu tiên, chúng ta định nghĩa các state sử dụng trong máy đọc tại class SyntaxState.

- Tiếp theo, chúng ta định nghĩa các phương thức kiểm tra tính hợp lệ của tên thẻ và tên attribute. Vì tên thẻ và tên attribute có quy tắc đặt tên giống nhau: chứa chữ cái hoặc chữ số, dấu gạch dưới, dấu gạch ngang hoặc dấu chấm (phương thức isNamedChar); kí tự bắt đầu có thể là một dấu gạch dưới, dấu hai chấm hoặc một chữ cái bất kì (phương thức isStartChar). Do đó chúng dùng chung hai phương thức trên.

- Biến INLINE_TAGS định nghĩa những thẻ mà HTML cho phép không cần thẻ đóng, như <img> hoặc <br>. Khi đọc đến những thẻ này, bộ đọc sẽ tự động thêm kí tự “/” cuối thẻ để well-formed thành XML.
- Class XmlSyntaxChecker
Đây chính là class hiện thực máy đọc cú pháp HTML mà bài viết đang hướng đến.

Tổng quan class XmlSyntaxChecker bao gồm một method chính là check() để thực hiện việc đọc hiểu cú pháp của nội dung HTML và chuyển đổi chúng thành nội dung XML đã được well-formed; một method phụ convert() để chuyển tập attribute bao gồm các cặp key-value về dạng chuẩn XML; một biến quote dùng để lưu trữ loại dấu nháy của value (nháy đơn hoặc nháy kép).
Chúng ta tiến hành import toàn bộ constant và static method chứa trong class SyntaxState đã định nghĩa ở trên vào sử dụng.
2.1 convert(): hàm convert có dạng như sau

- Phương thức trả về một chuỗi có dạng attribute1=“value1” attribute2=“value2”... Nếu không có attribute nào, phương thức trả về chuỗi rỗng.
- Trong đó, chúng ta thay thế mọi kí tự đặc biệt bằng tham chiếu entity của chúng đã được quy định trong XML, trước hết là kí tự “&”, sau đó là dấu nháy kép, dấu nháy đơn, kí tự “<” và kí tự “>”.
2.2 check(): hàm check nhận biến src làm nội dung HTML đầu vào, trả về nội dung XML đã được well-formed

- Chúng ta chuyển toàn bộ biến src thành một chuỗi các biến char lưu trong biến reader, để thực hiện vòng lặp đọc ra từng kí HTML.
- Biến writer là nơi ghi lại văn bản HTML đã được convert sang dạng XML well-formed làm kết quả trả về. Chúng ta sử dụng StringBuilder để tăng tốc trong việc xử lý string trên từng kí tự.
- Các biến openTag, closeTag, attrName, attrValue dùng để ghi nhận những giá trị hiện tại của thẻ mở, thẻ đóng, tên attribute và giá trị của attribute tương ứng, khi máy đọc gặp một thẻ bất kì. Biến attributes dùng để lưu toàn bộ attribute của một thẻ mở. Cờ isEmptyTag, isOpenTag, isCloseTag dùng để dánh dấu cho biết đây là một thẻ rỗng, một thẻ mở hoặc một thẻ đóng.
- Biến content để lưu giá trị hiện thời của character data.
- Stack dùng để thực hiện việc thêm thẻ đóng/mở bị thiếu cho nội dung HTML.
- Biến state dùng để quản lý trạng thái của máy đọc. Trạng thái khởi tạo ban đầu của máy là CONTENT (character data).
- Chúng ta bắt đầu việc đọc ra từng kí tự một của nội dung HTML đầu vào:

- Dựa trên các quy ước về kĩ thuật lập trình máy trạng thái đã thảo luận ở trên, chúng ta sẽ triển khai code theo Sơ đồ 1 (sơ đồ máy đọc cú pháp của HTML)
- Bắt đầu từ trạng thái CONTENT ban đầu, khi đang duyệt character data, nếu gặp phải một kí tự “<”, chúng ta đang gặp một thẻ bất kì, do đó chuyển trạng thái của máy sang OPEN_BRACKET và thực hiện thao tác ghi character data hiện tại vào writer (thay thế kí tự “&” bằng tham chiếu entity “&”).
- Ngược lại, nếu không gặp kí tự “>”, tiếp tục ghi nhận character data vào biến content.

- Ở trạng thái OPEN_BRACKET, chúng ta có 2 hướng rẽ nhánh – một là thẻ mở nếu gặp ngay một kí tự mở đầu tên tag, khi đó cờ isOpenTag được bật, và bắt đầu việc khi nhận tên thẻ mở (hàm setLength(0) của StringBuilder có tác dụng reset lại toàn bộ giá trị của biến). Hướng thứ hai là thẻ đóng nếu gặp ngay kí tự “/”, khi đó cờ isCloseTag được bật.


- Ở trạng thái OPEN_TAG_NAME, chúng ta tiếp tục ghi nhận tên thẻ mở nếu kí tự hiện tại vẫn hợp lệ với tên thẻ. Nếu gặp khoảng trắng, chúng ta chuẩn bị ghi nhận attribute của thẻ bằng cách reset lại biến attributes. Nếu gặp các kí tự khác, chúng ta chuyển đến các trạng thái tương ứng.


- Ở trạng thái TAG_INNER, chúng ta skip qua mọi khoảng trắng (bằng cách loop state), cho đến khi gặp được kí tự bắt đầu tên attribute. Khi đó chuẩn bị ghi nhận tên của attribute vào biến attrName. Tuy nhiên thẻ mở cũng có thể kết thúc ngay khi gặp kí tự “/” hoặc kí tự “>”.
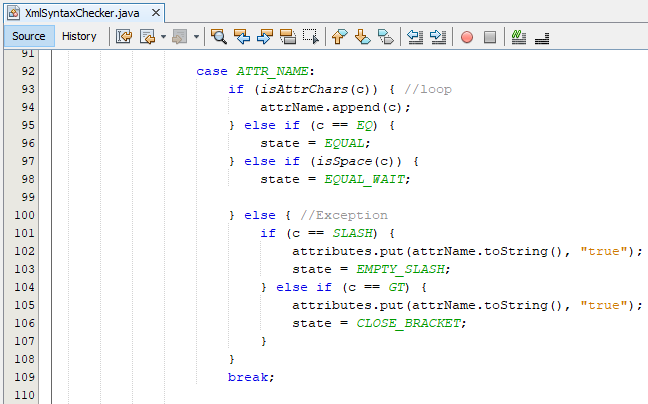

- Ở trạng thái ATTR_NAME, chúng ta tiến hành việc ghi nhận tên attribute và chỉ dừng khi gặp khoảng trắng hoặc gặp dấu bằng. Mệnh đề else cuối cùng là nơi diễn ra các event ngoại lệ (exception) chưa được định nghĩa trong sơ đồ trạng thái. Đôi khi attribute name không tiếp tục với value của nó nhưng lại kết thúc một cách đột ngột với kí tự “/” hoặc “>” - ở đây chính là trường hợp attribute không chứa value: ví dụ như <option checked> hoặc <option checked/>. Khi đó, chúng ta sẽ thêm value mặc định cho attribute là “true” và chuyển đến state với kí tự gặp được tương ứng.


- Ở trạng thái EQUAL_WAIT, các khoảng trắng sẽ được skip cho đến khi gặp được dấu bằng đầu tiên. Trường hợp ngoại lệ ở trạng thái này chính là máy đọc lại đọc được kí tự bắt đầu của tên một attribute khác, thay vì gặp được dấu bằng đầu tiên. Đây chính là trường hợp attribute không có value liên tiếp nhau: ví dụ <option checked selected>. Khi đó, chúng ta sẽ thêm value “true” mặc định cho attribute hiện tại, lưu vào tập attributes, tiến hành ghi nhận attribute tiếp theo và chuyển về lại trạng thái ATTR_NAME.


- Ở trạng thái EQUAL, chúng ta cũng skip mọi khoảng trắng cho đến khi gặp được dấu nháy đầu tiên. Khi đó, chúng ta lưu lại giá trị dấu nháy để nhận biết (nháy đơn hay là nháy kép), và tiến hành ghi nhận value của attribute. Tuy nhiên, với trường hợp value không được bọc trong cặp dấu nháy, ví dụ như <input type=text>, chúng ta sẽ tiến hành ghi nhận attribute, ngay khi gặp một kí tự bất kì không phải khoảng trắng và không phải kí tự báo hiệu đóng thẻ “>”.


- Ở trạng thái ATTR_VALUE_Q (Quoted), chúng ta liên tục ghi nhận value của attribute, và chỉ dừng lại khi gặp đúng loại dấu nháy mở mà chúng ta đã lưu vào biến quote ở trạng thái EQUAL. Khi đó tiến hành lưu attribute name và value hiện tại và tập attributes, chuyển ngược về TAG_INNER (để tiếp tục thu thập attribute của thẻ nếu còn).


- Ở trạng thái ATTR_VALUE_NQ (Not Quoted), ), chúng ta liên tục ghi nhận value của attribute, và chỉ dừng lại khi gặp phải kí tự kết thúc thẻ “>”, hoặc gặp phải khoảng trắng đầu tiên. Khi đó tiến hành lưu attribute name và value hiện tại và tập attributes, và chuyển đến state tương ứng tiếp theo.

- Ở trạng thái này, cờ isEmptyTag sẽ được bật lên để xử lý thẻ rỗng.
- Chúng ta đã xử lý xong các trạng thái của thẻ mở. Áp dụng kĩ thuật tương tự với thẻ đóng:


- Ở trạng thái waitEndTagClose, chúng ta skip qua mọi khoảng trắng cho đến khi gặp kí tự “>”.
- Cuối cùng, là trạng thái CLOSE_BRACKET. Ngay khi kết thúc một thẻ mở/đóng, ta sẽ tiến hành thu gom và xử lý fragment HTML hiện hành (bao gồm tên thẻ và các attribute nếu có) thành dạng well-formed XML và ghi vào biến đầu ra writer.


- Đầu tiên với trường hợp thẻ ghi nhận hiện tại đang là thẻ mở, chúng ta kiểm tra xem liệu thẻ mở này có phải một loại empty element được lưu trong INLINE_TAGS hay không, nếu phải thì bật cờ isEmptyTag lên. Sau đó tiến hành ghi nhận thẻ mở theo thứ tự: <tên_thẻ attribute=“value”.../>. Hàm convert (được mô tả ở mục 2.1) chuyển toàn bộ tập attributes thành chuỗi các key=“value” tương ứng. Nếu cờ isEmptyTag được bật, một kí tự “/” sẽ được thêm vào cuối thẻ.
- Stack chỉ dùng để push những thẻ mở (không phải thẻ rỗng – cờ isEmpty không được bật) vào để theo dõi việc đóng mở thẻ sau này.
- Tiếp theo, đối với trường hợp thẻ ghi nhận hiện tại đang là thẻ đóng, chúng ta lấy ra tên thẻ đóng và sử dụng stack để xử lý việc thiếu thẻ. Như đã thảo luận ở đầu bài viết, ta có 2 hướng giải quyết ứng với 2 trường hợp thiếu thẻ.
i. Thiếu thẻ mở: Chúng Ta kiểm tra thẻ đóng có tồn tại trong stack hay không. Nếu không, đây là thẻ đóng bị lỗi (thiếu thẻ mở), bỏ qua không xử lý nó.
ii. Thiếu thẻ đóng: Ngược lại, nếu thẻ đóng tồn tại trong stack, chúng ta tiến hành xử lý, theo hướng giải quyết đã nêu ra ở đầu bài viết.
- Sau khi xử lý xong, chuyển trạng thái dựa trên sơ đồ máy trạng thái tương ứng. Đây cũng là trạng thái cuối cùng của khối lệnh switch(state) và kết thúc vòng lặp for(reader)

- Sau khi thoát khỏi vòng lặp for(reader), chúng ta tổng hợp những dữ liệu còn sót lại (CONTENT theo sau tài liệu, các thẻ đóng còn thiếu ở cuối tài liệu), và trả về nội dung của biến đầu ra writer, kết thúc phương thức check().
- Class TextUtils:
Chúng ta đã hoàn thành xong máy đọc cú pháp HTML. Tuy nhiên, để dễ dàng sử dụng và tránh một số lỗi khác, ta không sử dụng trực tiếp class XmlSyntaxChecker, nhưng thông qua class TextUtils, bổ sung thêm một số phương thức tiền xử lý khác.

Về tổng quan, class TextUtils có 3 method chính:
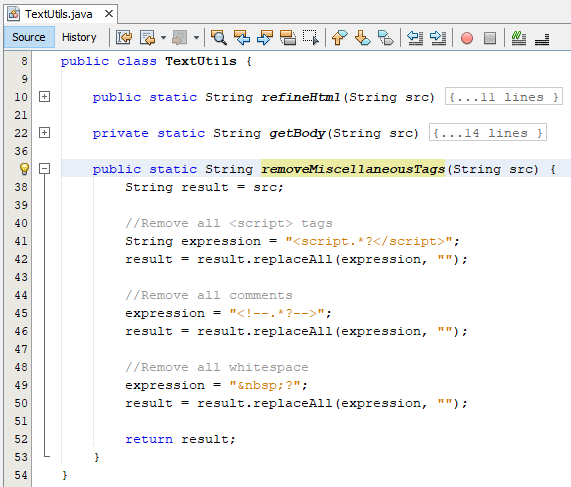
3.1 refineHtml():
Đây là phương thức chính khi xử lý và chuyển đổi từ định dạng HTML sang chuẩn XML.
Trước khi xử lý dữ liệu HTML, chúng ta sẽ tìm và loại bỏ những thẻ không cần thiết như comment và thẻ script (chứa code javascript trong đó có những kí tự có thể gây lỗi). Ngoài ra, vùng tập trung dữ liệu chủ yếu của tài liệu HTML nằm ở thẻ body. Do đó, chúng ta sẽ cắt toàn bộ thẻ body để thu hẹp vùng xử lý cho máy đọc.

3.2 getBody():
Hàm getBody có tác dụng cắt và trả về phần <body>...</body> từ tài liệu HTML thô ban đầu bằng cách sử dụng Regular Expression. (Xem thêm về Regular Expression tại http://www.vogella.com/tutorials/JavaRegularExpressions/article.html)

3.3 removeMiscellaneousTags():
Phương thức này sử dụng regular expression để loại bỏ những đoạn script, những đoạn comment và tham chiếu entity
VII. Kiểm tra kết quả:
Đầu tiên, ta kiểm tra tính đúng đắn của bộ đọc cú pháp (class XmlSyntaxChecker)

Kết quả sau khi chạy:

Tiếp theo, chúng ta kiểm tra tính đúng đắn của bộ well-formed TextUtils.
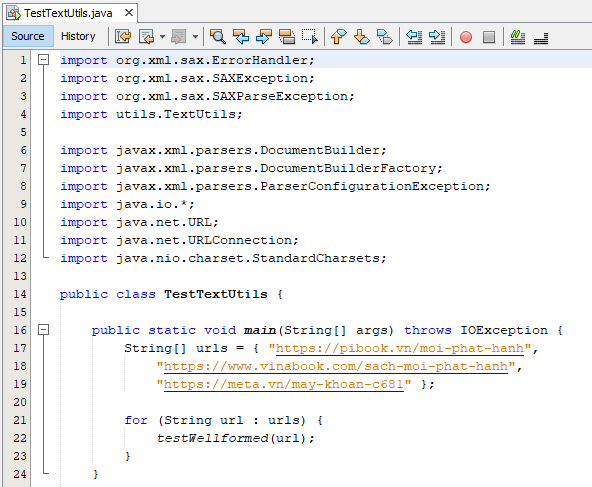
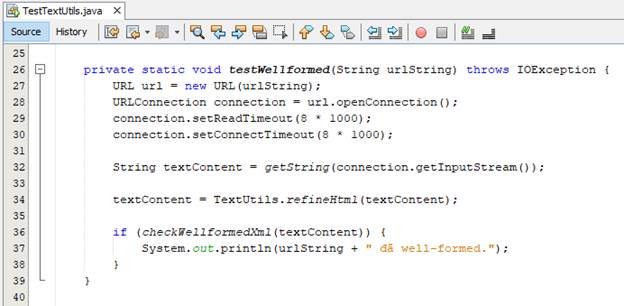



- Phương thức testWellformed() sẽ lấy nội dung HTML trực tiếp từ internet về, sau đó lấy ra dưới dạng String và thực hiện well-formed bằng class TextUtils
- Phương thức checkWellformedXml() sử dụng DocumentBuilder kết hợp với SAX parser để check well-formed tài liệu XML. Nó trả về true nếu tài liệu XML đã well-formed và quá trình parse diễn ra thành công, ngược lại trả về false.
Chạy thử, chúng ta được kết quả, nội dung HTML của cả 3 website đều đã được wellformed đầy đủ (quý vị có thể xuất kết quả dưới dạng file để tiện kiểm tra).

Cấu trúc của project

Chúc mừng quí vị đã hoàn tất việc triển khai và hiện thực bộ đọc và well-formed tài liệu HTML một cách linh động.
Kết quả của bài viết này vẫn còn một số điểm chưa hoàn thiện liên quan đến các tham chiếu entity được định nghĩa trong XML. Quý vị có thể áp dụng những ý tưởng của bài viết để phát triển thêm tính năng đọc cú pháp tham chiếu entity, phát hiện ra tham chiếu nào không hợp lệ mà loại bỏ. (ví dụ & hoặc { là những tham chiếu hợp lệ, cần giữ lại; &name=a là tham chiếu không hợp lệ, cần thay thế bằng &name=a)
Ở đây, chúng ta thấy rõ tầm quan trọng của kiến thức nền, về định nghĩa XML well-formed và cú pháp của HTML, kết hợp kĩ thuật lập “Máy trạng thái hữu hạn” sẽ giúp triển khai rất nhiều ý tưởng liên quan đến máy đọc và phân tích ngôn ngữ. Rất mong quí vị góp ý về nội dung bài viết này
Không có nhận xét nào:
Đăng nhận xét