Tác giả: Mai Vũ Cường
Mục đích: Chủ đề bài viết này nhằm hướng dẫn việc lấy dữ liệu trong quá trình crawl dữ liệu từ các web site (HTML tĩnh) có lỗi thiếu thẻ đóng </tag> sử dụng StAX (Streaming API for XML) Iterator API. Bài viết này đưa ra giải pháp cho việc lấy được dữ liệu của tài liệu XML đang xử lý mà không well-formed và tiếp tục thực hiện parse cho đến hết toàn bộ văn bản xử lý.
Yêu cầu:
· Nắm vững về các kiến thức của OO và cách thực lập trình với OOP, cụ thể là Java
· Nắm vững khái niệm về XML và cách viết một tài liệu chuẩn well-form (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-inh-nghia-cach-viet.html )
· Nắm vững cách sử dung các bộ Parser, cụ thể ở đây là bộ StAX (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/10/dung-stax-parser-e-xay-dung-ung-dung.html )
· Hiểu và đã thực hiện việc parse dữ liệu từ các trang web html (tham khảo các bài viết tại địa chỉ http://www.kieutrongkhanh.net/2017/06/su-dung-xml-parser-trich-xuat-du-lieu.html, http://www.kieutrongkhanh.net/2018/06/hien-thuc-bo-parser-html-bang-xslt.html, http://www.kieutrongkhanh.net/2017/12/trich-xuat-du-lieu-tu-trang-web-xu-ly.html )
Kiến thức tổng quát:
StAX – là bộ parser thực hiện parsing tài liệu XML theo cơ chế như sau
· Khi tài liệu XML được đưa vào bộ parser, toàn bộ tài liệu được kiểm tra well-formed
· Khi nội dung tài liệu kiểm tra xong và đóng, toàn bộ tài liệu được truy cập dưới dạng Stream và được nạp vào bộ nhớ từng phần tùy theo tiến trình duyệt tài liệu
· Sau đó, bộ StAX parser sẽ thực hiện việc đọc các thành phần theo chiều đi tới trong stream tùy theo sự điều khiển của ứng dụng và lấy giá trị theo yêu cầu của người dùng
· StAX parser có đặc tính tối ưu là bộ parse dạng pull, nó cho phép người sử dụng điều khiển quá trình xử lý. Nó cung cấp khá năng cho người dùng có thể dừng bộ parser bất cứ khi nào, có thể bỏ qua một số phần tử nhất định, có thể tạm dừng quá trình parse, có thể tiếp tục quá trình parse đã dừng
· StAX parser hỗ trợ multitple thread đối với ứng dụng và hỗ trợ nhiều người sử dụng cùng một lúc
· Cú pháp API của StAX rất đơn giản bởi vì nó hỗ trợ di chuyển trong Stream và đưa ra dữ liệu dạng tổng quát nhất cho người sử dụng
· StAX là bộ parser duy nhất hỗ trợ cơ chế đọc và ghi trên tài liệu XML
· StAX hỗ trợ cơ chế đọc tài liệu XML cực kỳ lớn và hỗ trợ xử lý với tốc độ duyệt khá tốt và phù hợp với thiết bị có bộ nhớ nhỏ và ít
· Lưu ý về StAX trong bài viết này
o HTML là một tài liệu XML không được well-form (VD: thẻ input và meta không có chứa thẻ đóng). Vì vậy, khi sử dụng bộ parse StAX, chúng ta cần lưu ý để bộ parse không bị dừng khi gặp lỗi không well-form.
o StAX là bộ parse tài liệu XML có thể cung cấp những thông tin liên quan đến tài liệu HTML như
§ Loại thẻ element theo tuần tự từ trên xuống từ trái qua
§ Tên thẻ
§ Giá trị thuộc tính của thẻ (nếu có).
o Vì vậy, để trích xuất được những dữ liệu cần thiết trên tài liệu HTML, chúng ta cần quan tâm đến vị trí và thuộc tính của thẻ chứa những dữ liệu đó trong tài liệu HTML.
Phương pháp xử lý mà chúng ta tiếp cận ở đây không phải là sửa tài liệu XML từ không well-formed trở thành well-formed trong quá trình parse. Ở đây, chúng ta đang thực hiện việc lấy dữ liệu của trang mà chúng ta đang crawl khi có lỗi well-formed là thiếu thẻ tag đóng và tiếp tục parse hay crawl dữ liệu tiếp tục mà không bị dừng lại
· Trong quá trình parsing dữ liệu, nếu phần nội dung tài liệu XML đang được xử lý chưa được well-formed, thì bộ StAX parse sẽ ném ra lỗi là XMLStreamException
· Chúng ta thực hiện catch message lỗi ném ra để thực hiện phân tích message lỗi. Từ message lỗi này, chúng ta tách lấy phần tên thẻ lỗi và tạo ra event thẻ đóng để đánh dấu việc hoàn tất một thẻ tag nhằm mục đính lưu trữ đúng dữ liệu đang cần xử lý cho các chức năng tiếp theo.
· Chúng ta cần biết vị trí các event thẻ đóng và mở để có thể lưu trữ được thông tin sản phẩm cần parse/crawl. Do vậy, cách thức nêu trên là một giải pháp để chúng ta lấy đúng thông tin cần xử lý và không thực hiện việc well-formed tài liệu XML.
Áp dụng định hướng nêu trên trong việc crawl dữ liệu từ một trang chưa well-form
Thực hiện crawl thông tin của laptop tại địa chỉ https://fptshop.com.vn/may-tinh-xach-tay/tu-25-30-trieu
· Tool và các công nghệ sử dụng
o Netbeans 8.2
o JDK 8
o JAXP (TrAX)
o Các plugin hỗ trợ inspect element trong các browser
· Các bước thực hiện
o Thực hiện truy cập trang web theo địa chỉ nêu trên trên browser, thực hiện inspect element trên trang. Chúng ta sẽ nhận thấy cấu trúc như hình bên dưới

o Tuy nhiên, nội dung các thẻ tag chưa được well-form

o Nếu nội dung này được đưa vào bộ StAX để parser dữ liệu thì chúng ta sẽ nhận được lỗi như sau

o Chúng ta nhận thấy trong thông báo lỗi này có vị trí xuất hiện lỗi và message lỗi với thông báo thẻ đóng bị thiếu. Với hình mình họa, chúng ta nhìn thấy thiếu thẻ đóng </li>
o Từ nhận định nêu trên và kết xuất của message được ném bởi exception, chúng ta có thể xử lý các lỗi well-form thiếu đóng </tag> bằng cách cắt phần tên tag trong message lỗi theo hướng tiếp cận ở bên dưới

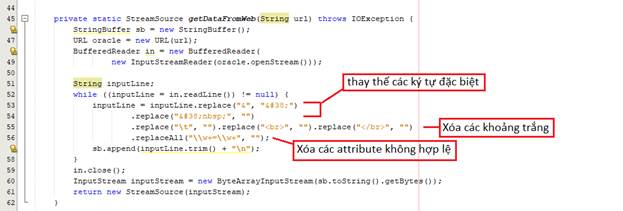
o Bước 1: lấy dữ liệu từ trang web (dưới dạng HTML) và chuyển thành StreamSource
§ Chúng ta thực hiện implement hàm thư việc thực hiện
· Lấy dữ liệu từ trang web thông qua địa chỉ url để chuyển thành Input Stream.
· Sau đó, dựa trên input stream có được chúng ta thực hiện việc chuẩn hóa dữ liệu thông quá việc thay thế các ký tự đặc biệt thành các entity references để tránh lỗi trong quá trình parse, các escapes sequence như \t – thẻ <br/> thanh khoảng trắng, và remove các attribute không hợp lệ ra khỏi stream đó.
o Bước 2: dùng StAX Iterator để định vị sản phẩm cần tìm
§ Chúng ta tiếp tục bổ sung hàm thư viện để lấy các giá trị của sản phẩm cần parse
§ Trong code này, chúng ta sẽ nuốt lỗi tại phần catch Exception để tránh việc bộ parse sẽ tiếp tục xử lý khi nội dung tài liệu đang bị xử lý không well-formed.

o Bước 3: dùng StAX Iterator để lấy thông tin sản phẩm và xử lý well-form
§ Chúng ta thực hiện tạo ra thư viện để thực hiện parse dữ liệu và xử lý lấy thông tin cần xử lý đối với phần tài liệu không well-formed do việc thiếu thẻ tag đóng và không cho bộ parse dừng để lấy hết toàn bộ sản phẩm
§ Các thành phần event chứa dữ liệu sau thẻ mở sẽ được đưa vào array list (đây chính là phần thông tin sản phẩm mà chúng ta cần lấy) để chuyển sang thành phần chức năng xử lý dữ liệu
§ Nội dung tiếp theo chúng ta cần quan tâm là làm sao biết được phần kết thúc thông tin của chúng ta là ở đâu?
§ Chúng ta không thực hiện việc correct tài liệu mà định hướng vào mục đích là lấy thông tin, cụ thể ở đây là lấy thông tin sản phẩm
· Trong quá trình xử lý, khi nội dung tài liệu được StAX parse mà không well-form, StAX sẽ tự động ném lỗi
· Chúng ta bắt lỗi này và thực hiện phân tích message lỗi. Sau đó, thực hiện cắt phần thông tin trong message để lấy tên thẻ còn thiếu
· Tạo Event cho thẻ đóng thiếu để đánh dấu việc kết thúc dữ liệu của một tag thông tin cung cấp cho chúng ta về sản phẩm. Sau đó, tiếp tục chạy bộ parse mà không cần quan tâm đến phần nội dung tài liệu đã xử lý qua.

o Bước 4: In dữ liệu của sản phẩm đã được well-form
§ Chúng ta xây dựng hàm thư việc để thực hiện duyệt toàn danh mục sản phẩm lấy được thông qua duyệt và lấy thông tin của các event trong list đó

o Bước 5: Tạo chương trình test thử những nội dung chúng ta vừa thực hiện ở các bước trên
§ Viết code hiện thực việc gọi hàm xử lý

§ Thực hiện build và test thử để nhận được kết quả của ứng dụng

§ Bài viết đã định hướng cho chúng ta việc lấy được các event hoàn chỉnh tập trung vào nội dung cần lấy. Trong ứng dụng cần khai thác dữ liệu, quí vị chỉ cần thực hiện parse các event kết quả trên thông qua List hay chuỗi String để lấy thông tin cần thiết và thực hiện xử lý
Quí vị vừa hoàn tất việc lấy dữ liệu từ tài liệu XML chưa well-formed, cụ thể ở đây là thiếu thẻ tag đóng do chúng ta thực hiện crawl dữ liệu từ HTML Tĩnh được kéo về trong quá trình chúng ta parse dữ liệu từ các website sử dụng StaX parser Iterator API
Hy vọng chủ đề này sẽ hỗ trợ quí vị trong việc parse thông tin từ các web site
Rất mong sự đóng góp của quí vị đối với nội dung bài viết này.
Không có nhận xét nào:
Đăng nhận xét