Trích xuất dữ liệu từ trang web, xử lý lỗi trong quá trình parse dữ liệu, xử lý dữ liệu có unicode, xây dựng cách thức chuyển đổi dữ liệu linh hoạt và trình bày dữ liệu kết hợp XSL có nhúng JavaScript
Tác giả: Nguyễn Công Chính
Mục đích: Chủ đề của bài viết này nhằm hướng dẫn cách thực hiện Scrapping Data (Parse dữ liệu từ websites) thông qua bộ parser StaX và cụ thể là StaX Cursor. Ngoài ra, bài viết còn hướng tới mục tiêu xử lý dữ liệu bằng cách chuyển dữ liệu đã scrapping từ websites thành XML thông qua việc Marshaller linh động với nhiều object có cấu trúc khác nhau. Cuối cùng, áp dụng XSLT trên trang JSP kết hợp JavaScript để có thể xem dữ liệu hiển thị ở browser cho người dùng.
Yêu cầu kiến thức cơ bản:
· Nắm vững khái niệm về ngôn ngữ lập trình Java, lập trình thao tác hướng đối tượng, cách thức sử dụng các method và các thư viện được cung cấp bởi ngôn ngữ Java và các thành phần có liên quan.
· Nắm vững khái niệm và cách sử dụng XPath.
· Nắm vững khái niệm và cách sử dụng của bộ parser StaX.
· Nắm vững cách viết tài liệu XSL và apply tài liệu XML với XSL.
· Nắm vững các khái niệm về XML và cách viết tài liệu XML well-formed
· Nắm vững về cơ chế Marshaller trong JAXB.
· Nắm vững kiến thức về XML schema (XSD) và cách vận dụng nội dung này trong ứng dụng phần mềm
Tools sử dụng:
- Netbeans 8.2.
- JDK 8.
Trong bài viết này, chúng ta sẽ thực hiện Scrapping dữ liệu từ 02 websites, cụ thể là “mediheal.vn” và “sakurabeauty.com.vn”.
Trước khi thực hiện việc Scapping Data, chúng ta cần phải xác định được cấu trúc để lưu trữ dữ liệu được parse về. Do đó, chúng ta sẽ xây dựng tài liệu XSD (XML Schema Definition) để định nghĩa cách thức tổ chức dữ liệu.
Tập tin Categories.xsd mô tả hệ thống có thể lưu trữ nhiều hơn một category để phân loại các sản phẩm trong hệ thống thành nhiều nhóm. Các category này đươc định nghĩa cấu trúc trong tập tin CategorySchema.xsd.
Nội dung định nghĩa được thể hiện như sau

Trong tập tin này, chúng tôi giới thiệu kỹ thuật tách schema thành từng định nghĩa riêng biệt, không thực hiện nhúng toàn bộ nội dung định nghĩa phức tạp gây khó hiểu cho người áp dụng.
Các thành phần schema sẽ được reference vào nhau thông qua lệnh import. Cú pháp của câu lệnh import yêu cầu xác định vị trí của tập tin schema được import và namespace được định nghĩa trong tập tin đó. Sau khi import, chúng ta cần phải khai báo namespace để reference đến schema chúng ta đã import để từ đó có thể sử dụng các thành phần import trong tập tin schema
Trong bài này, chúng ta thực hiện import việc định nghĩa các category có trong hệ thống chúng ta thông qua tập tin “CategorySchema.xsd” vào trong tập tin “Categories.xsd” đã nêu trên. Trong bài này, sau khi import xong, chúng ta phải định nghĩa prefix đến schema được import với tên là targer (dòng khai báo trong code là xmlns:target = “www.CategorySchema.com”). Để sử dụng được nội dung import chúng ta sử dụng theo cú pháp như sau
<xs:element ref=“target:Category” maxOccurs = “unbounded”/>
Định nghĩa cấu trúc category được lưu trữ trong hệ thống có cấu trúc như sau
· Mỗi category được phân biệt duy nhất qua CategoryID và nó là thuộc tính của category element
· Mỗi category đều có tên thể hiện qua element CategoryName và tập tên được qui định sẵn
· Mỗi category phải có phần mô tả của nó. Nội dung này được thể hiện thông qua element Description
· Mỗi category có tập sản phẩm được thể hiện thông element product được định nghĩa trong schema import (tập tin ProductSchema.xsd)
Nội dung định nghĩa ở trên được thể hiện trong tập tin CategorySchema.xsd như sau

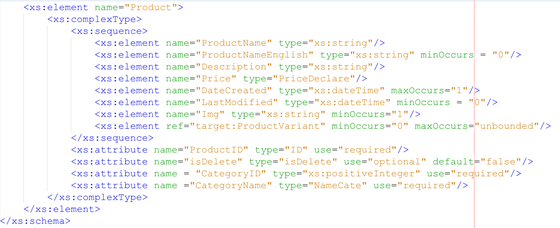
Tiếp theo là phần mô tả thông tin sản phẩm được thể hiện trong tập tin ProductSchema.xsd.
Một sản phẩm được mô tả với cấu trúc như sau
· Sản phẩm phải có duy nhất ID thông qua thuộc tính ProductID
· Sản phẩm có đang được sử dụng trong hệ thống hay không thông qua thuộc tính isDelete
· Sản phẩm thuộc về một category nào thông qua thuộc tính CategoryID và CategoryName
· Tất cả bốn thuộc tính nêu trên được tổ chức thành attribute của element Product
· Tên sản phẩm được thể hiện qua element ProductName và có thể trình bày với tên tiếng anh thông qua element ProductNameEnglish
· Sản phẩm sẽ được mô tả chi tiết thông qua element Description
· Sản phẩm có giá cụ thể thông qua element Price
· Sản phẩm có thông tin liên quan đến ngày bắt đầu có sản phẩm và lần cuối cùng thay đổi thông tin sản phẩm thông qua element tên là DateCreated và LastModified
· Sản phẩm sẽ có ít nhất một hình ảnh mô tả kèm theo thông qua element Img
· Một số đặc tính khác của sản phẩm được mô tả thông qua element ProductVariant, nội dung này được định nghĩa trong một tài liệu khác để import vào schema đang được mô tả


Tập tin ProductVariantSchema.xsd mô tả các thành phần phụ của sản phẩm nếu có với cấu trúc
· Mỗi thành phần có ID duy nhất thể hiện qua thuộc tính ProductVariantId
· Mỗi thành phần này thuộc về Product nào thể hiện thông qua thuộc tính ProductId
· Mỗi thành phần có SKU, giá và số lượng thể hiện thông qua element SKU, price, quantity
Các đặc tả này được mô tả như sau

Sau khi xây dựng được tài liệu XSD, chúng ta cần phải tạo những java object class tương ứng nhằm mục đích dữ liệu sau khi được scrapping từ websites sẽ được thể hiện lại qua các java object class đã được chúng ta miêu tả.
Để xây dựng java object class tương ứng với tài liệu XSD ở trên, chúng ta có nhiều cách tiếp cận. Ví dụ như sử dụng tools của Netbeans để có thể phát sinh tự động. Hay như sử dụng code để phát sinh các thành phần JAXB thông qua JDK.
Để tiện cho việc truyền dữ liệu, chúng ta sẽ tự tạo java object class mapping tương ứng với các schema đã nêu trên.
· Đầu tiên là cho tập các category, chúng ta tạo class jaxb_Categories với mô tả như bên dưới

· Tiếp theo chúng ta tạo class chứa các product với tên gọi jaxb_Products với mô tả như bên dưới

· Tiếp theo chúng ta khai báo kiểu dữ liệu ánh xạ với các định danh được dùng trong hệ thống thông qua class Enum

Lưu ý
· Quí vị có thể thấy rằng chúng tôi có sử dụng khai báo các mã kèm theo các định danh đã được khai báo ở cấu trúc file Enum – điều này là cần thiết bởi vì khi thao tác với các nội dung thuộc dữ liệu “UTF-8” với dữ liệu có dấu để có thể xử lý trên các công cụ và thư viện lập trình khác nhau nhằm tránh việc sai lệch khi xử lý unicode.
· Để có thể generate ra các mã dữ liệu đi kèm, chúng tôi đã hiện thực 2 method để hỗ trợ. Trong trường hợp quí vị cần sử dụng, việc đầu tiên là quí vị cần phải generate các mã với dữ liệu tương ứng với chuỗi đưa vào.
· Chúng ta có thể gọi riêng các phương thức này để phát sinh các mã Unicode cần thiết cho các định danh nhiều hơn trong nội dung bài đang thực hiện

· Chúng ta tiếp tục tạo class chứa từng product riêng biệt với tên gọi tbl_Products tương ứng với cấu trúc file “ProductSchema.xsd”.

Ở đây, chúng ta mapping tương ứng mỗi attribute trong schema với @XmlAttribute và element với @XmlElement
· Chúng ta tiếp mô tả class tbl_ProductCategories nhằm mô tả nhóm các danh mục sản phẩm

· Chúng ta tiếp mô tả class tbl_ProductVariants nhằm mô tả một số đặc tính của sản phẩm




Sau khi đã có được XSD lẫn java object class tương ứng, bây giờ chúng ta có thể đi scrapping dữ liệu từ websites.
Yếu tố quan trọng của việc scrapping dữ liệu là chúng ta cần phải xác định được rằng dữ liệu nào chúng ta cần lấy và dữ liệu đó hiện tại được trình bày trên web như thế nào.
Ở đây, chúng tôi xin lấy ví dụ của trang web “mediheal.vn” để nói rõ hơn ở phần này.

Thẻ tag “ul” với id = “product_filter” là nơi biểu diễn các category. Do đó, để lấy được tên của categories tương ứng, chúng ta cần truy xuất dữ liệu web từ thẻ ul này.

Theo hình trên, chúng ta dễ dàng nhận thấy được rằng mỗi product được biểu diễn ở 2 div
· div class= “thumbnail” giúp chúng ta lấy được hình ảnh của product
· div class= “text” giúp chúng ta lấy được thông tin của sản phẩm.
Sau khi đã xác định dữ liệu được bố trí ra sao, chúng ta bắt đầu đi xây dựng method để hỗ trợ việc clone toàn bộ dữ liệu có trên web. Dữ liệu này là dữ liệu thô chưa được validate. Do đó, khi clone dữ liệu từ websites về chúng ta cần phải kết hợp validate để dữ liệu được well-formed.

Trong code được mô tả trong hình trên,
· Khung đỏ thứ nhất thể hiện thông số cấu hình để hình thành message gửi về server để clone dữ liệu về. Server khi xử lý một message phải request thì sẽ xác định xem người dùng đang dùng trình duyệt gì trên nền platform hay hệ điều hành gì.
· Khung đỏ thứ hai ý hỗ trợ loại bỏ các thành phần dư thừa, cụ thể là các từ khóa đã mô tả trong code (quí vị có thể bổ sung thêm để có thể xử lý nhiều trang khác nhau) trong nội dung xử lý.
Sau khi có được dữ liệu đã clone về, chúng ta sẽ dùng bộ parser StaX để parse, trích xuất ra các dữ liệu cần thiết.

Trong quá trình parse dữ liệu, chúng ta cần thiết lập một số thông số xử lý thông qua phương thức setProperty. Ở đây, chúng ta sẽ cấu hình 4 thuộc tính:
· Thuộc tính thứ 1: IS_REPLACING_ENTITY_REFERENCES là thuộc tính hỗ trợ thay thế các entity bên trong tài liệu đang parse với chuỗi cấu hình đưa vào
· Thuộc tính thứ 2: IS_VALIDATING là thuộc để hỗ trợ việc validation trong quá trình parse dữ liệu. Ở đây, chúng ta không cần validation dữ liệu nên chúng ta sẽ thiết lập giá trị này là false
· Thuộc tính thứ 3: IS_SUPPORTING_EXTERNAL_ENTITES là thuộc tính hỗ trợ xử lý các entity được tham chiếu từ bên ngoài tài liệu đang parse
· Thuộc tính thứ 4: IS_COALESCING là thuộc tính để hỗ trợ đọc các nhóm ký tự
Tiếp theo là phần code xử lý còn lại của hàm staxCursorParser

Trong đoạn code trên, chúng ta thấy chuỗi so sánh có chứa ký tự đặt biệt “\u…”. Các ký tự trong chuỗi này sẽ hỗ trợ chúng ta trong việc so sánh dữ liệu chính xác khi trong ứng dụng có dùng chữ Unicode.
Tiếp theo đó là các code phần còn lại của hàm parser




Sau khi có dữ liệu, chúng ta thực hiện lưu các thông tin này vào trong jaxb Object để từ đó thực hiện lưu trữ dữ liệu ở Database

Phương thức saveToDatabase trong code nêu trên sẽ không đề cập ở tài liệu này bởi vì quí vị có thể sử dụng bất kể framework nào từ JDBC thuần đến JPA, EJB, ….
Nội dung tiếp theo của bài viết này, chúng ta trình bày kết quả lưu trữ được ra browser thông qua việc ứng dụng XSLT trên JSP. Trong phần này, ngoài việc nắm bắt kiến thức của XSLT thì quí vị có phải có kiến thức xây dựng ứng dụng với MVC trên web kết hợp giữa JSP và Servlet.
Để tăng tính tối ưu trong việc xử lý dữ liệu khi request đến server, chúng ta sẽ sử dụng ServletRequestListener – 1 interface được kế thừa từ EventListener để đón nhận tất cả các request được gửi từ client về phía server.

Trong một project lớn, chúng ta cần xây dựng method có tính chất tổng quát trong việc xử lý với nhiều hơn một đối tượng với nhiều đặt tính khác nhau để hạn chế việc xây dựng quá nhiều method trùng lặp về mục đích trong xử lý. Do đó, phương thức “marsalData” trong bài này đã được xây dựng tổng quát hóa nhằm mục đích cho phép marshall dữ liệu với bất kỳ object nào.

Tiếp theo, chúng ta viết code xử lý cho việc trình bày sản phẩm ra browser cho người sử dụng


Kế tiếp, chúng ta sẽ viết code xử lý trình bày giao diện trên trang jsp (Home.jsp). Code xử lý vận dụng XSLT lẫn Javascript để hỗ trợ việc view ra sản phẩm.

Để có thể viết được XSLT kết hợp với JSP trước hết chúng ta cần xác định được cần dữ liệu nào chúng ta sẽ view bằng XSLT, ở đây cụ thể là sản phẩm. Do đó,chúng ta viết layout sẵn cho trang web và chỉ việc import XSLT vào trang jsp.


Attribute “PRODUCTS” được lưu dưới dạng String trong ngôn ngữ javaScript (biến regObj) để dễ dàng thao tác và xử lý. Biến này sẽ được chuyển thành cấu trúc cây DOM thông qua sự hỗ trợ của DOMParser() trên code javaScript



Và kết quả sau khi chuyển từ String sang XML

Chúng ta tiếp tục viết code xử lý cho trang XSLT để kết hợp với JSP:

Do cấu trúc XML có khai báo namespace, tài liệu XSLT cũng cần khai báo lại namespace để bộ parser có thể xử lý và tìm kiếm đúng nội dung cần xử lý.
Sau khi có tài liệu XSLT, chúng ta import vào trang JSP

Chúng ta vửa hoàn thành xong việc dùng XSLT kết hợp với JSP để trình bày sản phẩm.
** Mở rộng: Trang web của chúng ta sau 1 khoảng thời gian nhất định cần phải có cơ chế để lấy được dữ liệu mới nhất ở dưới DB và cập nhật tự động lại lên web. Do đó, ở đây chúng tôi dùng xmlHttpRequest để gửi yêu cầu và JS để xử lý lại trang view.




Chúc mừng quí vị vừa hoàn thành xong việc parser dữ liệu từ trang web, tổ chức dữ liệu để lưu trữ và xử lý dữ liệu với các đặt tính động và áp dụng mô hình đồng bộ hóa dữ liệu cho người dùng trong quá trình xử lý.
Không có nhận xét nào:
Đăng nhận xét