Hiện thực bộ parser html bằng xslt
Tác giả: Nguyễn Lê Nhật Trường
Mục đích
Chủ đề bài viết này nhằm hướng dẫn cách thực hiện Scrapping Data (Parse dữ liệu từ websites với cấu trúc HTML) thông qua bộ Transformer API for XML (TrAX) sử dụng stylesheet (XSL). Trong bài này, chúng tôi sẽ giới thiệu cách tiền xử lý dữ liệu để đảm bảo tính well-form cho tài liệu XML trước khi apply xsl sử dụng ngay thư viện được Java cung cấp là URIResolver để cho thấy tính chất đơn giản trong việc tiền xử lý.
Yêu cầu
· Nắm vững về các kiến thức của OO và cách thực lập trình với OOP, cụ thể là Java
· Nắm vững khái niệm về cách sử dụng XPath (tham khảo lại bài Giới thiệu về XPath http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xpath.html ).
· Nắm vững và đã thực hiện toàn bộ nội dung của bài viết liên quan đến XSL phần 1 (tham khảo lại bài Style Sheets – Giới thiệu cách sử dụng và cách viết style sheet áp dụng cho XML – Extensible Style Language – XSL (Phần 1) http://www.kieutrongkhanh.net/2016/08/style-sheets-gioi-thieu-cach-su-dung-va.html ).
· Nắm vững khái niệm về XML và cách viết một tài liệu chuẩn well-form (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-inh-nghia-cach-viet.html )
Các tool sử dụng
· Netbeans 8.2.
· JDK 8.
Nội dung
1.1. Giới thiệu
· Về bản chất, chúng ta có thể thấy html là một dạng xml bán cấu trúc theo nghĩa có thẻ tag để xác định dữ liệu nhưng có thể lồng nhau không theo thứ tự bởi vì chúng được tạo ra để trình bày dữ liệu. Với định hướng đó, chúng ta hoàn toàn có thể dùng XPATH để truy suất vào dữ liệu bất kỳ nằm trong trang html. Bên cạnh đó, chúng ta có thể apply xsl để biến trang html thành xml với cấu trúc mà ta mong muốn.
· Mặc khác, trong XPATH có hỗ trợ chúng ta sử dụng XPath Function với hàm document để chuyển đổi String/URI/File path thành dom tree để dễ dàng truy vấn bên trong file xsl. Từ đó, chúng ta có thể sử dụng trực tiếp hàm document để load trang html mà chúng ta muốn xử lý thông qua đường dẫn url được nhập vào.
· Tuy nhiên, các trang html cần xử lý, thông thường sẽ có một số trang không đảm bảo well-form nên việc xử lý well-form trước khi apply xsl là điều cần thiết. Trong bộ transformer API, interface URIResolver (tham khảo tại địa chỉ https://docs.oracle.com/javase/7/docs/api/javax/xml/transform/URIResolver.html ) với hàm resolve được hệ thống kích hoạt khi hàm document (tham khảo tại địa chỉ https://www.w3schools.com/xml/func_document.asp ) được gọi để thực hiện tiền xử lý các nội dung trong streaming sau khi chuyển đổi. Chúng ta sẽ sử dụng hàm này để tiến hành tiền xử lý các kết quả trả về dựa trên URI được gọi.
1.2. Các bước thực hiện
· Trong bài viết này, chúng ta sẽ thực hiện Scrapping dữ liệu từ page “https://vi.wikipedia.org/wiki/Thể_loại:Thực_vật_được_sử_dụng_trong_Đông_y” và các sub page có liên kết trong page trên.
· Mô hình tổng quát của việc xử lý sẽ như sau
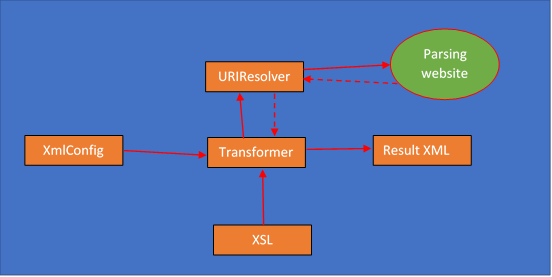
· Bước 1: Tiền xử lý dữ liệu của trang web
o Tạo class để implement URIResolver nhằm tiền xử lý trang web không well-form

§ Hiện thực hàm resolver để chỉ xử lý các URI từ trang https://vi.wikipedia.org/
§ Argument href chính là URI được truyền từ hàm document của file xsl.
§ Hàm preProcessInputStream là hàm chúng ta sẽ hiện thực phần kiểm tra và chỉnh sửa html string để đảm bảo luật wellform trước khi đưa vào apply xsl.
§ Vì mỗi trang web khác nhau sẽ tồn tại những lỗi wellform khác nhau, và mục tiêu của bài này không đi sâu về mặt xử lý webform cho trang html. Vì thế nên hàm preProcessInputStream bên dưới đây chỉ mang tính chất tham khảo.

**Lưu ý: Dòng 50-52 (vùng khoanh đỏ) ở trên là dòng bắt buộc phải có, vì bộ parser mà transformer đang dùng chưa hỗ trợ việc dùng default namespace để truy vấn dữ liệu bằng XPATH trên cây DOM.
· Bước 2: Hiện thực bộ parser
o Tạo class để thực hiện bộ parse thông qua cơ chế apply xsl

o Hàm crawl nhận vào 2 đối số là
§ configPath: đường dẫn đến file xml config
§ xslPath: đường dẫn đến file style sheet.
§ Sau khi khởi tạo transformerFactory, chúng ta dùng hàm setURIResolver để chỉ định transformer api sử dụng bộ resolver này để xử lý dữ liệu khi hàm document trong xsl được gọi. Sau đó, chúng ta chỉ việc transform xml với các nội dung cấu hình để tiến hành đem dữ liệu về xử lý
o Tạo file cấu hình cho việc xử lý parsing
· Chúng ta sử dụng cấu hình được mô tả bằng xml để cung cấp link page cấp 1 cho file xsl. Việc này góp phần giúp việc chỉnh sửa đường link sau này dể dàng hơn mà không cần phải cập nhật lại code của server.
o Nội dung file có cấu trúc như bên dưới

o Trong hình minh họa ở trên, chúng ta sử dụng attribute link để lưu trữ link cấp 1 mà chúng ta cần crawl và attribute host để xsl xử lý các link cấp 2 trở đi dể dàng hơn.
Chúng ta vừa hoàn tất xong nội dung cấu hình và chuẩn bị cho việc parse dữ liệu
· Bước 3: Phân tích cấu trúc website cần parse để tạo file xsl cho việc parsing dữ liệu
o Chúng ta sẽ thưc hiện với trang có hình minh họa bên dưới – trang cấp 1

o Phần khoanh đỏ ở trên chính là những dữ liệu của trang cấp 1 cần phải lấy. Chúng ta sử dụng công cụ inspect element để xác định cấu trúc cần lấy

o Khi thực hiện inspect trang HTML, chúng ta dễ dàng nhận thấy các dữ liệu cần lấy được nằm trong thẻ div có id=”mv-pages” và các tên các loại thuốc cần lấy có XPATH tính từ thẻ div trên là .//div[@class='mw-category-group']//li/a . Do vậy, chúng ta có thể hiện thực xsl như sau để tiến hành parse trang dữ liệu trên.

§ Ở khung đỏ số 1: chúng ta gọi hàm document với đối số link được lấy từ file XML config và load dữ liệu từ trang cấp 1, lưu vào biến listDoc.
§ Ở khung đỏ thứ 2: chúng ta áp dụng XPATH đã inspect ở trên để lấy ra thẻ a chứa dữ liệu cần lấy. Sau đó, chúng ta lưu lại name và đường dẫn đến trang cấp 2 ở các phần bên dưới khung đỏ.
o Như vậy chúng ta đã lấy được dữ liệu từ trang cấp 1, tiếp theo, dựa trên dữ liệu lấy được, ta tiến hành phân tích dữ liệu từ trang cấp 2.

o Với cách phân tích tương tự như ở trên, chúng ta dễ dàng có được xsl để lấy các phần dữ liệu cần thiết như bên dưới:
§ Xsl thu thập các nội dung chi tiết

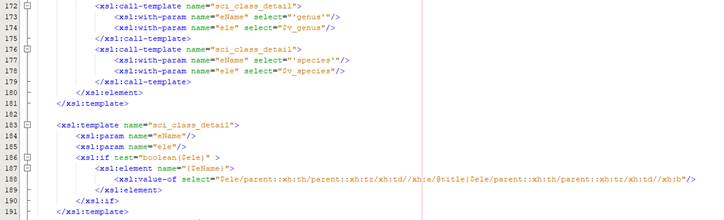
§ Xsl thu thập phần hình ảnh

§ Tổng hợp nội dung từ 2 xsl con ở trên
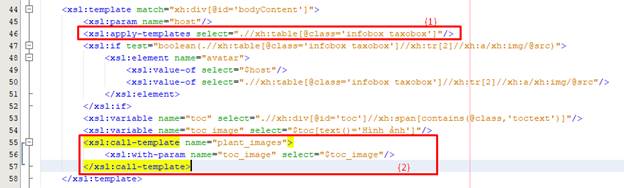
**Lưu ý: Do chúng ta đang apply template từ file XML config, nội dung XPATH trong tài liệu xsl dùng để truy vấn trên trang html có thể gây ra sai sót về ngữ nghĩa vì HTML có cấu trúc tùy tiện. Do vậy, chúng ta sẽ sử dụng cú pháp .// thay vì // để chọn chính xác context mà chúng ta cần xử lý
§ Chúng ta liên kết phần nội dung ở cả trang cấp 1 và trang cấp 2 lại như sau:

· Ở phần màu xanh dương, chúng ta tiến hành gọi hàm document để load dữ liệu ở trang cấp 2, lưu vào biến detailDoc. Sau đó, chúng ta dùng chính biến này để apply template được định nghĩa ở trên.
· Như vậy ta đã hoàn tất phần tạo file xsl thu thập dữ liệu từ cả 2 trang cấp 1 và cấp 2.
· Bước 4: Test thử ứng dụng với nội dung mà chúng ta đã xây dựng ở trên
o Chúng ta xây dựng hàm main để test thử như sau
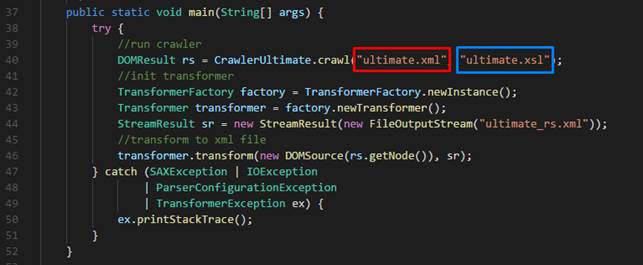
§ Trong code của hình trên, file ultimate.xml chính là file config xml và file ultimate.xsl là file style sheet.
o Kết quả chúng ta nhận được tập tin ultimate_rs.xml như sau

Chúc mừng quí vị đã hoàn thành xong việc parse dữ liệu mà không cần viết parser theo cách thông thường mà sử dụng việc apply style sheet với trang HTML để có được kết quả để xử lý.
Rất mong quí vị đóng góp cho chủ đề này. Hẹn gặp quí vị ở một chủ đề khác.
Không có nhận xét nào:
Đăng nhận xét