Trích xuất dữ liệu từ website sử dụng Multithreading và xây dựng các class tổng quát để hỗ trợ tính đa dạng khi khai thác ứng dụng
Tác giả: Nguyễn Thế Phương
Mục đích: Nội dung bài này hướng dẫn cách tối ưu trong việc khai thác dữ liệu lớn tận dụng khả năng của máy tính có nhiều CPU hay nhiều nhân – Core kết hợp với hệ điều hành hỗ trợ đa luồng – multi-threading để tăng hiệu suất và tốc độ trong quá trình khai thác và xử lý dữ liệu. Chúng tôi sẽ định hướng cách chia nhóm công viêc cho các thread thực hiện trong quá trình cào dữ liệu từ một trang web khác đem về để tổ chức thành dữ liệu khai thác trong hệ thống đang được xây dựng.
Trong bài viết này, chúng tôi có định hướng đến việc xây dựng bộ khai thác dữ liệu với các tính năng cơ bản để từ đó phát triển thành các công cụ mở rộng cho việc khai thác một trang web cụ thể và dễ dàng tích hợp khai thác các trang mới cho hệ thống mà không cần chỉnh sửa quá nhiều code thông qua kế thừa và lớp chuẩn/tổng quát để tạo tính linh hoạt cho ứng dụng.
Kiến thức yêu cầu
· Nắm vững về các kiến thức của OO và cách thực lập trình với OOP, cụ thể là Java
· Nắm vững khái niệm về XML và cách viết một tài liệu chuẩn well-form (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-inh-nghia-cach-viet.html )
· Nắm vững cách sử dung các bộ Parser, cụ thể ở đây là bộ StAX (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/10/dung-stax-parser-e-xay-dung-ung-dung.html )
· Nắm vững khái niệm về JAXB, cách tạo JAXB Object (tham khảo tại địa chỉ http://www.kieutrongkhanh.net/2016/10/jaxb-chuyen-oi-xml-schema-hay-dtd-tro.html ).
· Biết cách xây dựng một ứng dụng JavaEE, kết nối với hệ quản trị cơ sở dữ liệu sử dụng JDBC.
· Các định nghĩa liên quan đến JPA và cách thực kết nối dữ liệu sử dụng JPA (tham khảo tại địa chỉ http://www.kieutrongkhanh.net/2016/08/ung-dung-jpa-vao-mvc2-ket-hop-javaee6.html ). Nội dung liên quan đến việc sử dụng singleton pattern trong JPA (link tham khảo singleton pattern)
· Nắm vững các khái niệm về thread trong lập trình java (link tham khảo) (link tham khảo) và các nội dung có liên quan để lập trình thread để tránh xung đột, tránh race condition và đảm bảo mutual exclusion với ngữ nghĩa tại một thời điểm chỉ có một đối tượng ghi hay thay đổi giá trị trong vùng tài nguyên (link tham khảo synchronized method, synchronized statements)
· Các định nghĩa và sử dụng kiểu dữ liệu dạng Generic trong Java (link tham khảo)
Công cụ
- Netbeans IDE 8.1
- Tomcat server 8.x
- Jdk 8.
- Thư viện hô trợ EclipseLink (JPA 2.1)
-
Ý tưởng cơ bản của việc tách thread khi crawl data
- Với mỗi Domain cần xử lý, chúng ta sẽ tạo 1 thread để crawl data. Chúng ta cụ thể công việc này với việc lấy danh sách url của các category mà chúng ta cần xử lý.
- Với mỗi category trong danh sách nêu trên, chúng ta sẽ tạo ra 1 thread con để crawl data mà chúng ta quan tâm (ví dụ như chúng ta cần lấy số lượng trang sản phẩm của category này).
- Với mỗi trang sản phẩm trong category đang xử lý, chúng ta sẽ tạo thêm 1 thread con để lấy danh mục các sản phẩm.
Trong bài viết này, chúng ta sẽ khai thác dữ liệu từ 2 websites: “myboss.vn” và “azaudio.vn”. Để khai thác dữ liệu từ hai trang này, chúng ta sử dụng bộ StAX parser(StAX Iterator API) để parsing dữ liệu.
Các bước cơ bản để crawl dữ liệu
- Khi khai thác dữ liệu từ bất cứ một url nào, chúng ta đều phải tạo connection đến url đó rồi sau đó lấy InputStream từ connection để đọc dữ liệu.
- Khi đọc dữ liệu, chúng ta không cần lấy hết nguyên trang html mà chỉ lấy 1 đoạn chứa dữ liệu mà chúng ta cần xử lý.
- Sau khi lấy được đoạn XML cần xử lý, chúng ta sẽ tạo StAX Iterator (trả về XMLEventReader) để duyệt dữ liêu.
- Qua các nội dung đề cập ở trên, chúng ta nhận thấy có 2 methods được sử dụng rất nhiều, đó là:
o BufferedReader getBufferedReaderForURL(String urlString): Lấy BufferedReader để đọc dữ liệu từ Url.
o XMLEventReader parseStringToXMLEventReader(String xmlSection): Tạo StAX Iterator từ XML string.
- Dựa trên các định hướng đã nêu, chúng ta sẽ tạo một BaseCrawler có 2 methods này để tất cả các Crawler khác dễ dàng extend các class nhằm mục đích khai thác dữ liệu từ các trang web khác

Quản lý Thread
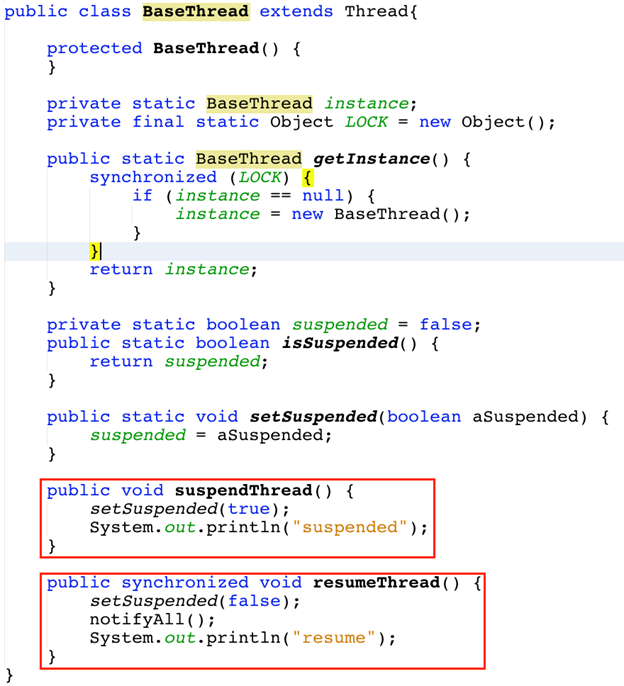
· Chúng ta cũng xây dựng luôn class Thread cơ sở để hỗ trợ chúng ta vận hành các Thread trong ứng dụng của chúng ta
o Để quản lý được việc khai thác dữ liệu tốt hơn thì ta phải có những method để pause và resume các thread crawler.
o Vì các method Thread.stop(), Thread.suspend(), Thread.resume() đã deprecated nên trong bài viết này sẽ sử dụng flag và wait(), notifyAll() để pause và resume các thread.
o Cụ thể cách làm là:
§ Khi muốn pause các thread, chúng ta chỉ cần set biến flag isSuspended = true
§ Trong quá trình hệ thống vận hành, các thread crawler sẽ kiểm tra biến isSuspended này, nếu thấy isSuspended = true thì thread sẽ gọi hàm wait().
§ Khi muốn resume các thread, chúng ta chỉ cần set biến isSuspended = false rồi gọi hàm notifyAll() để thông báo đến các thread crawler.
§ Chúng ta sẽ tạo 1 class để quản lý các thread crawler, cung cấp 2 method là suspendThread() và resumeThread()
§ Trong các thread crawler ta chỉ cần kiểm tra nếu isSuspended thì gọi hàm wait() để tạm dừng thread cho đến khi có notify.

§ Lưu ý:
· Hàm notifyAll(): chỉ gọi các thread đã bị wait() bởi cùng monitor với object monitor hiện tại thức dậy. Do đó, trong các thread crawler chúng ta phải dùng chung 1 monitor trong các thread crawler để gọi hàm wait(). Monitor này cũng là monitor dùng để gọi hàm notifyAll().
· Trong bài viết này, ch úng ta đang dùng BaseThread.getInstance() làm monitor(instance duy nhất của BaseThread).

Qui trình thực hiện crawl dữ liệu
Đầu tiên, chúng ta sẽ tiến hành Crawl data từ trang “myboss.vn”
· Bước 1: Tạo Thread để crawl data và lấy list các categories.
o Chúng ta truy cập vào trang www.myboss.vn và thực hiện việc inspect element. Chúng ta dễ dàng nhận thấy phần catgories đang được chứa trong thẻ <ul> phía dưới thẻ <a href="thiet-bi-choi-game-c1" title="THIẾT BỊ CHƠI GAME"></a>

o Chúng ta thực hiện tạo class MybossCategoriesCrawler kế thừa từ class Base Crawler để lấy các categories thông qua hai phương thức hàm được hiện thực như bên dưới
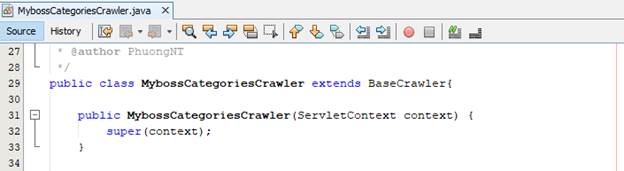

· Chúng ta thực hiện tạo thread thông qua Java class với tên MyBossThread kết thừa từ class BaseThread và implements Runnable. Trong đó, chúng ta xây dựng việc lấy categories sử dụng hàm Map<String, String> getCategories(String url) của class MybossCategoriesCrawler

· Bước 2: Sau khi lấy được link của các category rồi, chúng ta sẽ tạo cho mỗi Category một Thread con để khai thác dữ liệu. Cụ thể ở đây là lấy số lượng trang sản phẩm của category.
o Chúng ta quay lại inspection tiếp tục trang đang xử lý

o Chúng ta sẽ lấy số lượng trang của từng category, đoạn dữ liệu mà chúng ta cần lấy được chứa trong thẻ <div id=”phantrang”>. Bên cạnh đó, link của trang cuối được chứa trong thẻ <li class=”last”>
o Chúng ta xây dựng class MybossCrawler để thực hiện công việc này. Class này sẽ kế thừa từ bộ BaseCrawler và implement cơ chế để có thể vận hành với Thread (implement Runnable)


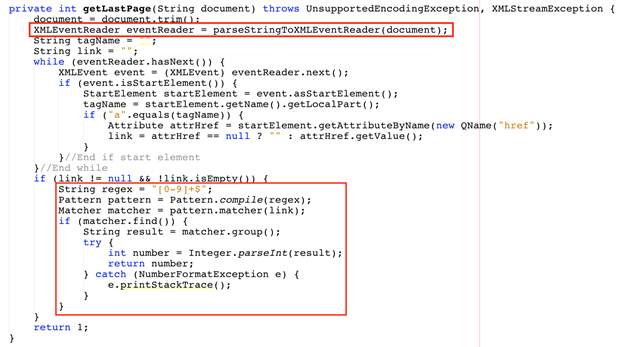
o Thực hiện tạo thread để lấy số lượng trang sản phẩm của từng category thông qua class MybossThread. Chúng ta bổ sung thêm code vào hàm run để thực hiện mục đích này như giải thích bên hình dưới

· Bước 3: Với mỗi trang sản phẩm của category, chúng ta tạo 1 Thread con để lấy list products.
o Chúng ta quay lại trình duyệt và đi vào từng Link của sản phẩm

o Đoạn dữ liệu chứa List Products của một trang, được chứa trong thẻ <ul class=”thumnail”>
o Khi click các thẻ li này ra, phần dữ liệu của một product mà chúng ta cần lấy

· Chúng ta xây dựng class MybossEachPageCrawler như là một thread để lấy các sản phẩm trong trang


· Sau khi hoàn tất việc lấy các sản phẩm, chúng ta thực hiện bổ sung thêm code vào class MyBossCrawler để thực hiện nhiệm vụ này trong phần tiếp theo của hàm run

· Chúng ta đã hoàn tất xong việc lấy các sản phẩm cùng với các danh mục sản phẩm từ myboss.vn.
· Đối với trang azaudio.vn, quí vị có thể làm tương tự các nội dung đã nêu trên thông qua việc implement các class kế thừa từ việc lấy category, lấy số trang category, lấy danh mục sản phẩm và thông tin sản phẩm

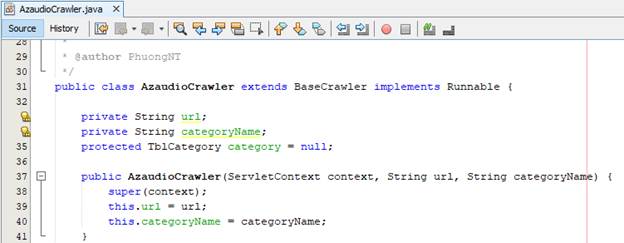









· Tuy nhiên, trong quá trình xử lý, chúng ta còn lưu trữ các thông tin xuống DB. Các nội dung tiếp theo sẽ hỗ trợ chúng ta thực hiện việc lưu trữ dữ liệu khi sử dụng thread trong quá trình xử lý như đã nêu trên
Cách sử dụng DAO – Data Access Object (đối tượng dùng để ánh xạ dữ liệu giữa bộ nhớ và DB) với multithreading và phương pháp đảm bảo tính tin cậy của dữ liệu trong quá trình sử dụng và lưu trữ trong cơ chế lập trình thread
Chúng ta dễ dàng nhận thấy rằng các class DAO sử dụng trong nội dung thực hiện để đưa dữ liệu crawl về để xử lý và đưa xuống DB đều có 5 methods: create(), update(), delete(), findByID(), và getAll(). Do đó, chúng ta sẽ tạo class BaseDao có implement sẵn 5 methods này nhằm mục đích dễ dàng vận dụng đối với các nguồn dữ liệu khác khi ứng dụng nâng cấp hay bảo trì.

Trong nội dung code trên, chúng ta đã sử dụng T và PK là kiểu Generic nhằm mục đích tạo ra các kiểu dữ liệu tùy ý khi sử dụng thực tế, không bị bó buộc khi viết code lẫn biên dịch chương trình, có thể nói nó có thể sử dụng kiểu được định nghĩa khi ứng dụng vận hàn (run-time). Các kiểu này sẽ được định nghĩa khi tạo class DAO kế thừa – extend từ class BaseDao.
T ở đây là DTO tương ứng với DAO hiện tại, còn PK là kiểu dữ liệu của primary key của DTO.
entityClass là Class của của DTO, dùng để xác định kiểu dữ liệu khi thực hiện transaction.
Nội dung tiếp theo trong hình bên dưới là việc chúng ta sẽ xây dựng thư viện hỗ trợ kết nối với database sử dụng JPA


Với cách hiện thực ứng dụng có nhiều thread chạy cùng lúc và insert xuống database trên mỗi trên (như các nội dung hướng dẫn trong phần crawl dữ liệu đã nêu ở các phần trên), chúng ta phải sử dụng singleton pattern và synchronized để tránh việc insert trùng lặp dữ liệu
Chúng ta đi sơ lược một chút kiên thức về synchronized và singleton cùng kết hợp trong nội dung công việc mà chúng ta đang thực hiện
· Với Synchronized Statements
· Cú pháp: Synchronized(Lock){//do something}
o Với Lock được coi là monitor, có thể là một biến bất kì
o Nội dung phần xử lý sẽ được viết trong phần block code {}.
· Khi chương trình thực thi đoạn code synchronized, hệ thống sẽ tạo Lock theo monitor để khoá đoạn code trong {}, với mục tiêu mỗi monitor thì chỉ cho 1 thread thực thi đoạn code {}. Sau khi code thực thi xong hệ thống mới mở khoá để đối tượng khác có thể vào xử lý.
· Nếu biến lock mà chúng ta truyền vào là một object duy nhất, thì đoạn code synchronized sẽ cho 1 thread truy cập trong một lúc. Nếu biến lock truyền vào có thể là 5 objects khác nhau thì đoạn code synchronized này có thể cho tối đa 5 threads thực thi cùng một lúc.
· Trong ứng dụng, chúng ta chỉ cần 1 instance của ProductDao để làm việc với database, vậy chúng ta sẽ áp dụng singleton pattern cho ProductDao:
o Đầu tiên, chúng ta tạo Constructor với modifier là private, để tránh việc tạo instance tuỳ ý.
o Sau đó, chúng ta khai báo biến instance có kiểu dữ liệu là ProductDao, và modifier cũng là private.
o Sau đó, chúng ta sẽ tạo 1 method để get instance của ProductDao là: getInstace(). Hàm này sẽ kiểm tra nếu biến instance = null thì sẽ tạo mới ProductDao, sau đó sẽ return instance.
o Nhưng vì ứng dụng của chúng ta đang chạy multithreading, nên nếu như có nhiều threads cùng truy cập vào method getInstance() cùng một lúc khi instance đang bằng null, thì những threads này sẽ tạo mới ProductDao, và ứng dụng của ta sẽ tồn tại nhiều instance của ProductDao. Do vậy, chúng ta phải dùng Synchronized Statements để khoá đoạn code kiểm tra instance = null và new ProductDao, giới hạn chỉ 1 thread được truy cập trong một thời điểm.
o Với lý do nêu trên, bài viết đang sử dụng biến LOCK có modifier là final, để biến LOCK chỉ có một giá trị duy nhất.
· Nói một cách tổng quát, chúng ta đã áp dụng singleton pattern thành công với thread safe.
Chúng ta hiện thực class ProductDao như hình bên dưới

Tuy nhiên, chúng ta vẫn còn một vấn đề liên quan đến việc truy cập đồng thời. Các method của ProductDao vẫn có thể bị nhiều thread truy cập cùng một lúc và insert dữ liệu xuống database. Nếu điều này xảy ra, chúng ta sẽ không kiểm soát được việc insert dữ liệu trùng lặp. Do đó, chúng ta sẽ sử dụng Synchronized method để xử lý vấn đề này.
· Synchronized method cũng tương tự như synchronized statements, với những method có chữ synchronized phía trước. Với cách thức này thì với mỗi instance, tại một thời điểm method này chỉ một thread thực thi.
· Trong ứng dụng, chúng ta chỉ có duy nhất 1 instance ProductDao, chúng ta thực hiện synchronized method saveProductWhenCrawling(TblProduct product) với mục đích tại một thời điểm chỉ cho một thread thực thi nhằm tránh việc insert trùng lặp dữ liệu xuống DB.
Chúng ta hiện thuộc luôn lớp CategoryDao để lưu trữ các danh mục sản phẩm và áp dụng các nội dung tương tự như ProductDao đã được định hướng ở trên


· Lưu ý
o Với hàm createCategory thuộc class không sử dụng singleton pattern, chúng ta chỉ cần sử dụng synchronized statements là đã có thể an toàn khi insert xuống database.
o Các lớp entity sử dụng trong bài viết này như sau






Phương pháp Quản lý Thread
Với các thread crawler, chúng ta sẽ cho chúng chạy khi deploy. Do vậy, chúng ta sẽ tạo một ServletContextListener và thực hiện start thread ở method contextInitialized
AzaudioThread và MybossThread đã giới thiệu trong phần đầu là 2 threads chính để khai thác dữ liệu từ 2 trang “azaudio.vn” và “myboss.vn”
Trong method contextInitialized, chúng ta new 2 threads của AzaudioThread và MybossThread và start() cho threads bắt đầu khai thác dữ liệu

Cấu trúc của project tổng quát sau khi chúng ta thực hiện như sau



Chúng ta có thể test thử Project và thêm các câu lệnh System.out.println vào trong hàm contextInitialized để thấy được quá trình parse dữ liệu tại thời điểm chúng ta deploy ứng dụng


Kết quả, database chúng ta có được dữ liệu parse về là
· Bảng TblCategory

· Bảng TblProduct


Chúc mừng quí vị đã hoàn tất cách xử lý ứng dụng crawl dữ liệu, xử lý và đưa xuống DB lưu trữ sử dụng thread để có thể chạy nhiều hơn một tác vụ trong cùng một lúc, đặc biệt nếu như máy tính của chúng ta có nhiều hơn một CPU hay một nhân để tăng hiệu suất trong xử lý nhưng vẫn đảm bảo tính tin cậy của dữ liệu được xử lý và lưu trữ
Rất mong sự đóng góp của quí vị về chủ đề này. Hẹn gặp quí vị ở một chủ đề khác.
share code di ban oi
Trả lờiXóa