GOM NHÓM VÀ LỌC DỮ LIỆU VỚI BỘ INTERCEPTOR ĐƯỢC XÂY DỰNG TỪ CÁC FILE STYLESHEET
Tác giả: Mã Hoàng Nhật Phi
Mục đích: Chủ đề của bài viết này đưa ra cách xử lý dữ liệu từ một file XML gồm nhiều thành phần dữ liệu nhưng có định dạng khác nhau thành một dạng chuẩn chung cho việc xử lý. Bài viết định hướng theo cách kết hợp các XSL lại với nhau, xem file XSL như một filter để dùng chúng như là interceptor trong việc lọc dữ liệu nhằm hạn chế các xử lý quá phức tạp trên cùng một file XSL. Bài viết phân chia thành hai phần chính. Phần đầu tiên là gom nhóm và chuyển đổi thành dữ liệu có cấu trúc. Sau đó, thực hiện định dạng dữ liệu đồng nhất.
Yêu cầu:
· Nắm vững khái niệm về XML và cách viết một tài liệu chuẩn well-form (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-inh-nghia-cach-viet.html )
· Có kiến thức về XML Schema (tham khảo thêm bài viết tương ứng tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-schema-inh-nghia-cach.html )
· Nắm vững cách sử dung các bộ DOM API (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-dom-inh-nghia-dom-api-va.html )
· Nắm vững khái niệm về cách sử dụng XPath (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xpath.html ).
· Nắm vững cách sử dung các bộ SAX Parser (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/10/su-dung-sax-parser-e-tim-kiem-du-lieu.html )
· Nắm vững cách sử dung JAXB (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/10/jaxb-chuyen-oi-xml-schema-hay-dtd-tro.html )
· Nắm vững và đã thực hiện toàn bộ nội dung của bài viết liên quan đến XSL (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/style-sheets-gioi-thieu-cach-su-dung-va.html & http://www.kieutrongkhanh.net/2016/08/style-sheets-gioi-thieu-cach-su-dung-va_29.html).
·
Biết cách và thực hiện crawl dữ
liệu và hoàn chỉnh thông tin crawl được
dưới dạng có cấu trúc (tham khảo bài viết
tại địa chỉ http://www.kieutrongkhanh.net/2018/12/topic-su-dung-mo-hinh-may-trang-thai.html và http://www.kieutrongkhanh.net/2018/12/su-dung-mo-hinh-may-trang-thai-state.html)
Các tool sử dụng:
· Netbeans 8.x
· JDK 8
I. Đặt vấn đề
Giả sử, chúng ta cần xử lý tài liệu xml bao gồm các thông tin về company, product và account. Trong đó, thông tin của company và product được lấy tương ứng từ hai domain là abc.com, xyz.vn. Tuy nhiên, account lại được lấy dữ liệu từ hệ thống nội bộ. Do lấy từ hai domain khác nhau về khu vực địa lý nên định dạng dữ liệu của một số thành phần trong product và company hoàn toàn khác nhau.
Mục tiêu của chúng ta là phải gom nhóm dữ liệu theo domain và chuẩn hóa định dạng để cung cấp thông tin cho một chức năng xử lý trong hệ thống. Bài viết này chỉ dừng ở chỗ hoàn tất quá trình chuyển đổi dữ liệu thành thông tin.
Để cho dễ hiểu hơn, chúng ta có mẫu tài liệu chứa thông tin của công ty như hình bên dưới
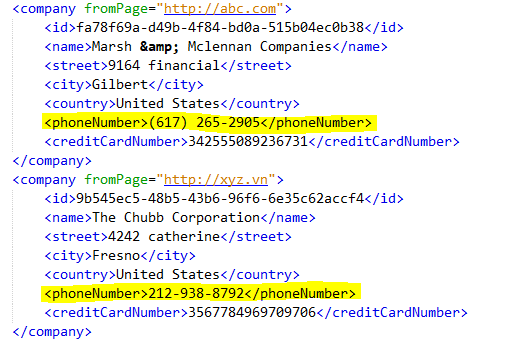
Chúng ta dễ dàng nhận thấy dữ liệu từ domain abc và xyz khác nhau về định dạng số điện thoại. Chúng ta sẽ chuẩn hóa định dạng dữ liệu theo format (xxx) xxx-xxxx.
Tương tự như trường hợp trên, chúng ta có mẫu thông tin về 02 sản phẩm từ 02 domain với định dạng thể hiện như bên dưới
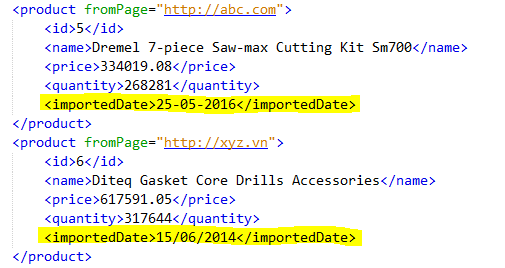
Dữ liệu của hai product có định dạng ngày tháng khác nhau. Chúng ta sẽ định dạng tất cả ngày tháng theo định dạng dd-MM-yyyy
Với các nội dung nêu trên, chúng ta sẽ thực hiện gom nhóm, lọc dữ liệu, tổ chức lại định dạng dữ liệu theo định hướng kết xuất như hình bên dưới


Chúng ta định hướng mô hình xử lý cho việc gom nhóm và lọc dữ liệu như sau

Việc chia nhỏ qui trình lọc dữ liệu ra nhiều XSL sẽ giúp
· Quá trình lọc dữ liệu trở nên linh hoạt, dễ dàng sửa chữa, không tập trung quá nhiều xử lý phức tạp vào cùng một file XSL,
· Xử lý từng nhóm dữ liệu mục tiêu theo các bộ interceptors khác nhau
· Dễ dàng thay đổi thứ tự các file xsl lọc dữ liệu theo ý muốn của người cấu hình.
Để thuận lợi cho việc thực hiện theo nội dung bài viết, chúng ta tải tài liệu xml được minh họa trong bài viết tại địa chỉ: https://github.com/mahoangnhatphi/sample_miscellaneous_xml_documents. Trong git repository này bao gồm hai file là data.xml (thành phần định danh fromPage là attribute) và data_fromPage_is_tag.xml (thành phần định danh fromPage là child node)
II. Nội dung
1. Aggregation
Chúng ta sẽ thực hiện gom nhóm dữ liệu từ việc crawl dữ liệu thô từ các domain. Trong nội dung bài viết này, chúng ta sẽ không đề cập đến việc crawl dữ liệu bởi vì việc crawl dữ liệu bao gồm việc crawl và chuẩn hóa dữ liệu thành dữ liệu hoàn chỉnh có thể xử lý là một nội dung lớn và tốn rất nhiều công đoạn. Các nội dung này chúng tôi đã đề cập tại phần nội dung yêu cầu đầu tiên của bài viết này.
Chúng ta thực hiện tạo một file XML Schema với cấu trúc mô tả như hình bên dưới với mục tiêu cấu hình về các thành phần phân biệt giữa dữ liệu lấy từ trang web cần xử lý

Sau đó, chúng ta thực hiện generate ra JAXB class để tiện cho việc hiện thực hóa.

Chúng ta tạo ra một abstract class để làm khuôn mẫu cho các class xử lý gom nhóm. Ở đây, chúng ta tạo ra abstract class để xác định các thông tin truyền vào để xử lý và xây dựng một interface kiểu dữ liệu dùng chung cho tất cả bộ parse dữ liệu trong quá trình xử lý với mục tiêu dễ dàng thay đổi trong quá trình phát triển và bảo trì ứng dụng.
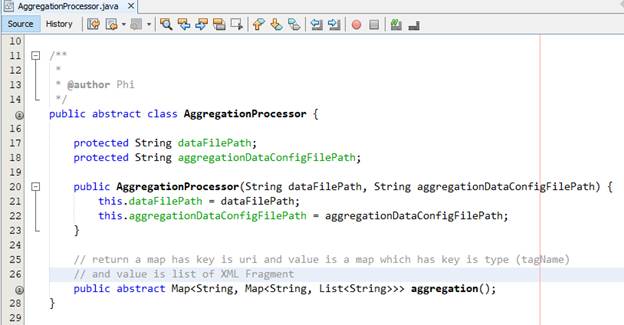
Ở đây, bài viết nhận đường dẫn của tài liệu xml nguồn nhằm thể hiện ý tưởng cho việc xử lý. Tuy nhiên, trong thực tế, chúng ta nên chuyển xml về thành String hoặc Stream trong quá trình xử lý (thay đổi tên tham số thành định hướng đón nhận một tài liệu XML dưới dạng String hay Stream) để chúng ta linh hoạt hơn trong quá trình xử lý.
Chúng ta cần phải implement Interface aggregation theo 02 đính hướng đó là sử dụng parser là DOM API và SAX Parser.
Option 1 – Sử dụng DOM API
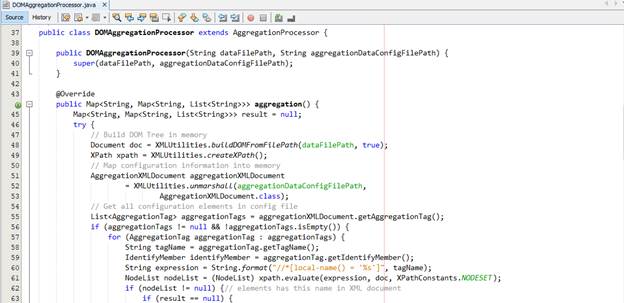

![]()
Để thuận lợi trong quá trình xử lý, chúng ta tạo một interface chứa các constant dùng chung trong quá trình trình xử lý.

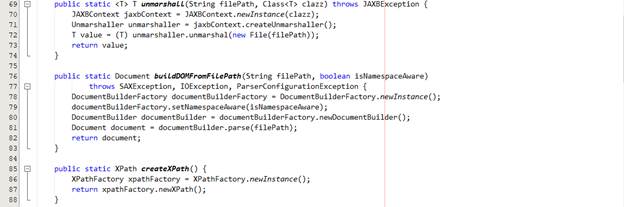
Hình bên dưới là các phương thức hỗ trợ cho việc xử lý của chúng ta. Chúng ta xây dựng bộ Utilities có tên là XMLUtilities để cung cấp các tiện ích về unmarshall config file, tạo cây DOM, tạo Xpath để truy vấn và chuyển đổi Node thành String, ..
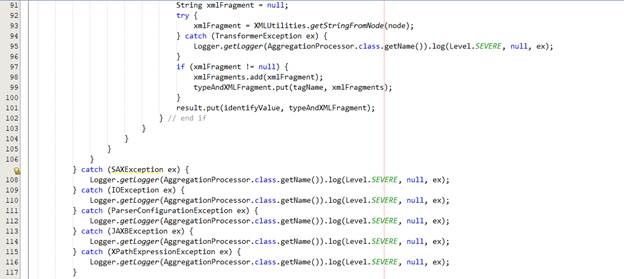
Chúng ta thực hiện
· Unmarshall để lấy thông tin từ file config được cung cấp.
· Parse dữ liệu XML của nội dung xử lý thành cây DOM
· Thực hiện truy vấn dữ liệu trên cây DOM với XPath
· Sau đó, bổ sung dữ liệu tìm được với các category tương ứng.
Định hướng cụ thể đó là
· Tìm ra các tagName đã được xác định trong file cấu hình
· Sau đó, xét xem thành phần định danh giữa các thẻ này là attribute hay child node để có mệnh đề Xpath tương ứng.
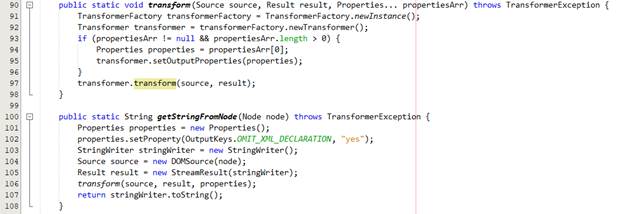
· Ở đây, chúng ta chuyển Node về String mà không dùng kiểu Node vì bản chất xml fragment là text và điều này giúp cho ta không ràng buộc về kiểu dữ liệu do mỗi parser có một kiểu dữ liệu khác nhau, từ đó ta sẽ dễ dàng chuyển đổi class để thực hiện gom nhóm mà không thay đổi quá nhiều.

![]()
Chúng ta thực hiện chạy thử để xem tài liệu xml nguồn ban đầu đã được gom nhóm chưa. Chúng ta có kết quả như sau:

Chúng ta có thể dùng kiểm tra kết quả bằng cách sử dụng tính năng search trong Netbeans áp dụng cho tập dữ liệu mẫu data.xml

Như vậy, chúng ta đã thấy kết quả gom nhóm đã chính xác theo từng trang trong đó lại được gom nhóm theo loại dữ liệu bên trong chứa các XML fragment. Đây sẽ là bước đầu tiên để lọc dữ liệu theo từng nhóm.
Option 2 – SAX Parser: Chúng ta thực hiện tạo một class kế thừa từ AggregationProcessor như ở option 1:
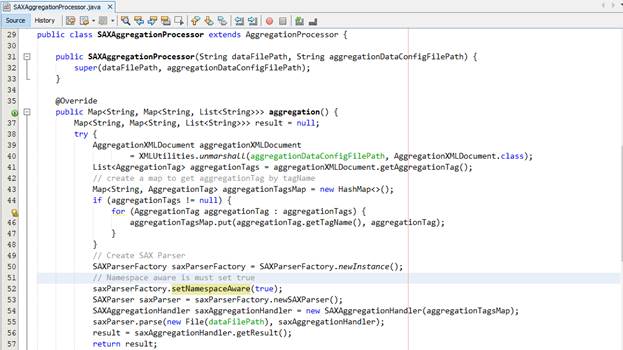

Chúng ta cần thiết lập cho bộ parser biết rằng tài liệu xml cần hỗ trợ việc xử lý có named qualified nên chúng ta thiết lập thông số như dòng thứ 52.
Chúng ta cũng thực hiện unmarshall để lấy thông tin từ file config được cung cấp để gom nhóm tài liệu XML nguồn.
Bên cạnh đó, chúng ta tạo class SAXAggregationHandler kế thừa DefaultHandler để xử lý XML bằng SAX Parser:
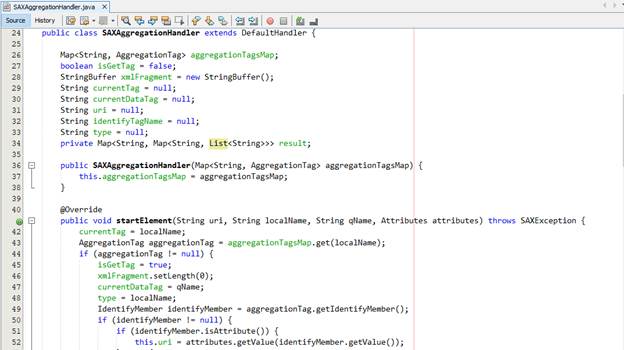

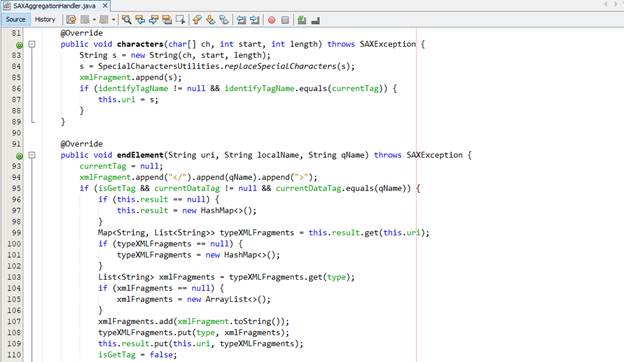

Ở đây, chúng ta đang thực hiên xử lý giản lược ba event chính là startElement, characters và endElement. Cụ thể như sau:
· Tại event characters, do bộ parser tự chuyển kí tự đặc biệt từ predefined entity về kí tự nên chúng ta phải thực hiện một bước convert ngược lại thành predefined entity khi ghi xuống StringBuffer chứa nội dung fragment đang xử lý.
· Ở startElement, chúng ta sẽ dùng khái niệm override namespace để xác định namespace cụ thể của tag này là gì và gán prefix đã có trong tài liệu nguồn cho chính nó, còn lại việc xử lý lấy thành phần identity là tương tự chỉ thay đổi xử lý khi IdentityMemember là attribute hay child node của node hiện hành do SAX Parser là forward-only nên phức tạp hơn ở DOM Api. Chúng ta sẽ lưu các giá trị parser đi qua vào một StringBuffer là xmlFragment sẽ là biến chứa XML Fragment mà chúng ta đã trích xuất. Bất kì kí tự nào có liên quan đến xml fragment đều được đẩy vào StringBuffer này.
· Cuối cùng tại event endElement, chúng ta đưa fragment lấy được vào đúng nhóm của nó trong biến chứa các kết quả và khởi tạo lại các biến theo dõi.
· Chúng ta xây dựng class hỗ trợ như SpecialCharactersUtilites

Trên thực tế, dữ liệu để map kí tự đặc biệt như là predefined entity trong quá trình xử lý không cần phải chuyển đổi thì chúng ta nên tạo ra một file properties để lưu trữ nhằm tạo nên tính linh hoạt trong quá trình bào trì cho ứng dụng.
Chúng ta thực hiện thay đổi nhỏ trong hàm kiểm tra kết quả như với DOM Api

Chúng ta có thể đổi tài liệu xml nguồn thành data_fromPage_is_tag.xml để kiểm tra hai bộ gom nhóm với DOM Api và SAX. Chúng ta sẽ có kết quả hoàn toàn tương tự.
Như vậy, chúng ta hoàn toàn có thể linh hoạt thay đổi các bộ parser khi có tham số đầu vào giống nhau và kiểu dữ liệu trả về giống nhau. Tùy vào dữ liệu nguồn và yêu cầu mà ta có thể lựa chọn bộ Parser phù hợp.
2. Interceptors
Chúng ta thực hiện tạo một file XML Schema:

Chúng ta sử dụng JAXB để generate schema này thành class phục vụ cho quá trình xử lý.
Chúng ta tạo một class util phục vụ cho việc chuyển đổi giữa URI và alias. Việc đang định danh một dữ liệu thông qua URI và loại dữ liệu được lấy từ trang web cần xử lý, alias là một giải pháp hạn chế lỗi vì việc dùng URI trong file config khá dài dòng và mang lại khả năng xảy ra lỗi sai sót cao.
Chúng ta tạo một class URIAliasDictonary như một util.


Đây đóng vai trò như một class helper giúp đỡ chúng ta trong quá trình xử lý chuyển đổi giữa URI và alias để tránh sai sót. Ở đây, chúng ta có hai map có thể xem như hai từ điển tra cứu tạo ra hai chiều thuận tiện cho việc tra URI-alias cũng như alias-URI.
Chúng ta tạo một file XML Schema chứa mô tả cấu hình của interceptor sẽ như thế nào cho từng loại dữ liệu từ trang web.

Chúng ta tạo ra một XML Document-instance của Schema trên.
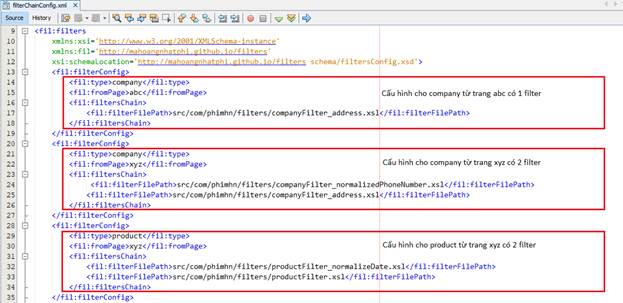

Chúng ta thực hiện generate JAXB class của XML Schema để chuẩn bị cho quá trình xử lý tiếp theo.

Như đã phân tích tại phần I, dữ liệu của company từ trang abc.com đã theo định dạng mong muốn. Tuy nhiên trang xyz. chưa được format dữ liệu theo như mong đội. do vậy, chúng ta sẽ cho dữ liệu từ trang xyz.vn đi qua nhiều hơn một filter so với abc.com để lọc dữ liệu theo một format chung. Tương tự, dữ liệu ngày tháng năm từ trang xyz cũng bị sai định dạng ngày tháng năm cần đi qua thêm một filter nữa để chuẩn hóa dữ liệu.
Chúng ta có thể thấy các filter được cấu hình theo loại dữ liệu và từ trang nào (đã thay thế bằng alias để thuận tiện quá trình cấu hình). Thứ tự của các filterFilePath trong filtersChain sẽ là thứ tự mà xml fragment sẽ đi qua trong quá trình lọc dữ liệu. Chúng ta có thể dễ dàng thay đổi vị trí của các filter mà xml fragment sẽ đi qua. Qua cách tiếp cận trên, chúng ta thấy vai trò quan trọng của file config này.
Chúng ta sẽ có tương ứng 4 file xsl để thực hiện filter dữ liệu.
i) Filter cho company chuẩn hóa số điện thoại

Chúng ta xử lý với thẻ phoneNumber là con của company còn các loại khác chúng ta copy lại như cũ. Chúng ta sẽ chuyển định dạng của phoneNumber về giống với chuẩn (xxx) xxx-xxxx
ii) Filter cho company xử lý address.
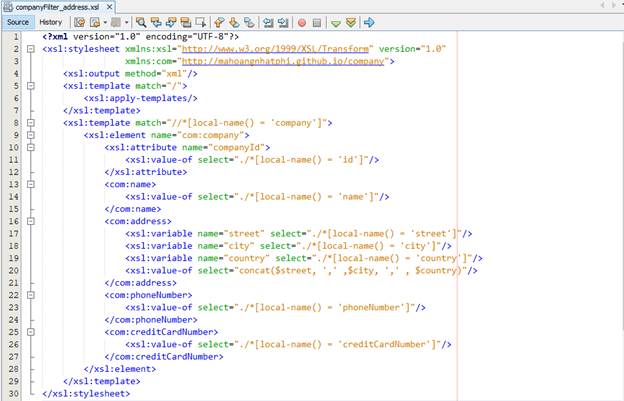
Chúng ta thực hiện biến id thành attribute và đổi địa chỉ thành một thẻ address duy nhất để dễ dàng cho quá trình xem địa chỉ.
iii) Filter cho product xử lý định dạng ngày tháng năm

Cũng tương tự company, chúng ta thực hiện xử lý thẻ importedDate là con của product còn các thẻ khác chúng ta copy lại. Chúng ta thay thế các dấu / thay bằng – trong nội dung của thẻ importedData.
iv) Filter cho product xử lý chuẩn hóa các element và attribute

Chúng ta chuyển đổi cấu trúc biến id thành attribute và importedData cũng thành attribute. Bên cạnh đó, chúng ta thêm priceUnit để xác định đơn vị tiền tệ của hai trang web vì đang giả sử khác khu vực địa lý.
Chúng ta tạo một class là InterceptorProcessor đóng vai trò là class nhận dữ liệu đã gom nhóm theo <uri, <type, xmlFragments>> và cũng trả về một dạng như <uri, <type, xmlFragments>>.
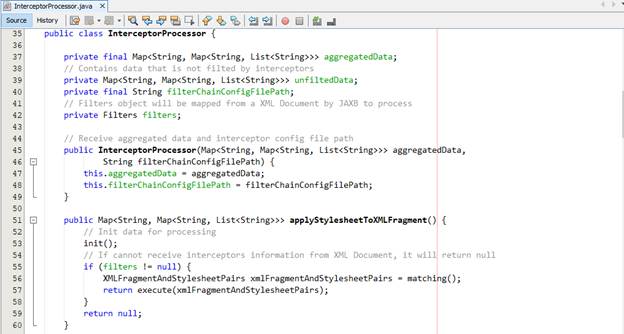






Chúng ta thực hiện matching giữa các XML fragment với các interceptors mà nó phải đi qua đã được cấu hình trong file config. Sau khi quá trình matching này, chúng ta thực hiện gọi execute để cho các xml fragment được đi qua interceptors và lọc dữ liệu. Phần dữ liệu không được cấu hình để lọc ta sẽ cho vào loại unfilted data có cấu trúc trả về giống với dữ liệu đã lọc. Ở đây, hàm applyStylesheetToXMLFragment trả về kết quả cho việc xử lý, còn các fragment chưa qua xử lý chúng ta sẽ cho phép lập trình viên lấy ra khi cần thông qua hàm getUnfiltedData.
Chúng ta xây dựng các class helper như sau:
· Class XMLFragmentAndStylesheetPair: Class này đóng vai trò như một khuôn mẫu chứa thông tin đã matching giữa XML fragment và list chứa thứ tự các đường dẫn của interceptor
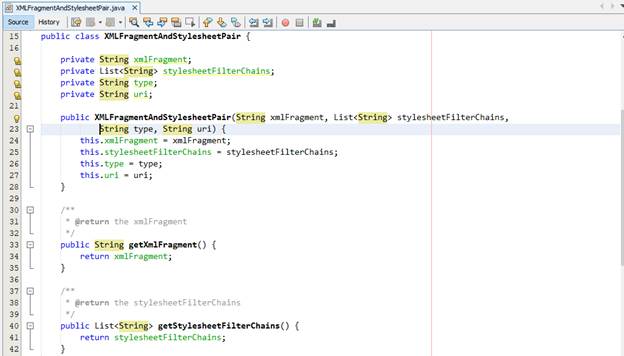

.
· Class XMLFragmentAndStylesheetPairs: Class này đóng vai trò bao đóng list các cặp xml fragment và các interceptors đã matching.

Chúng ta thực hiện gọi InterceptorsProcessor để đưa các XML Fragment đã gom cụm theo từng loại của từng trang đi qua các bộ lọc đã được cấu hình. Chúng ta thực hiện bổ sung hàm đã kiểm tra quá trình gom nhóm ở trên như sau.

Khi thực thi tử, chúng ta nhận được kết quả sau khi các nhóm dữ liệu đã đi qua Interceptors
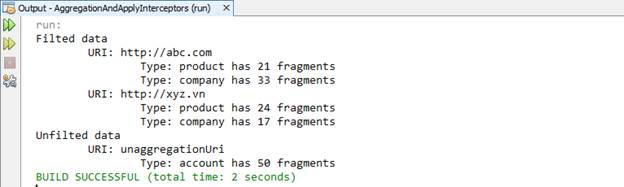
Như vậy, chúng ta đã có được các XML Fragments đã được gom cụm và lọc dữ liệu thông qua các interceptors. Chúng ta có thể lưu lại hoặc xử lý tiếp với các XML fragment này theo ý của người lập trình. Trong phạm vi bài viết này, chúng ta sẽ thực hiện động tác ghi file để thể hiện kết quả của hai quá trình trên, quí vị có thể dùng các XML fragment đã qua bộ lọc này theo ý mình tùy vào mục đích sử dụng.
Chúng vừa mới xem số lượng fragment theo trang và loại, để xem chi tiết từng xml fragment đã được đi qua các interceptors chúng ta chuyển tiếp sang phần 3 để xuất kết quả ra thành file.
3. Xuất kết quả
Trong nội dung bài viết này, chúng ta sẽ thực hiện xuất file ra gồm hai phần là filted data và unfilted data. Chúng ta đã chia các tài liệu xml nguồn ra theo từng trang URI và type cụ thể và đưa các list các xml fragments này đi qua các bộ interceptors tương ứng. Bây giờ, chúng ta sẽ thực hiện để ghi các list xml fragment này theo trang và theo loại thành từng file riêng và ghi các dữ liệu chưa lọc theo nhóm được tổ chức thành hai folder như sau:

Chúng ta thực hiện tạo một abstract class cho quá trình xử lý khi xuất file có thể dễ dàng thay đổi quá trình xử lý ghi file.

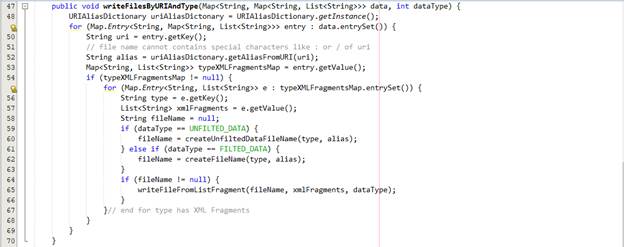

Chúng ta thực hiện abstract các hàm writeFilesByURIAndType. Đây là hàm sẽ thực hiện ghi các file theo uri và type. Ở đây, chúng ta có một tham số là dataType là tham số xác định xem đây là loại dữ liệu đã lọc hay chưa lọc. Từ đó, chúng ta cung cấp ra bên ngoài hai giao diện là writeFiltedDataToFilesByURIAndType và writeUnfiltedDataToFilesByURIAndType. Hai abstract method là createFileName và createUnfiltedDataFileName sẽ là method mà concrete class kế thừa abstract class phải override chứa quy tắc tạo ra tên khi ghi xuống file của hai loại dữ liệu là đã lọc và chưa lọc.
Chúng Ta thực hiện cài đặt một concrete class cho FileWriteProcessor là FileWriteProcessorImpl
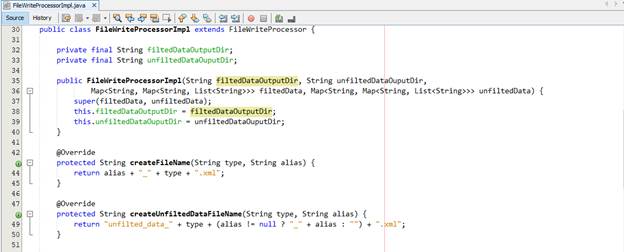

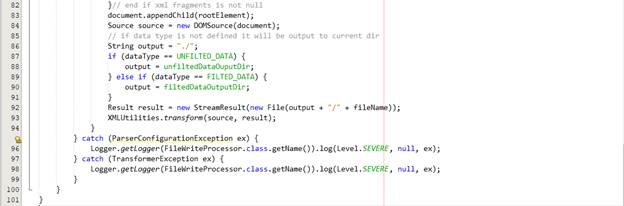
Khi convert từ String sang Node, chúng ta sẽ gặp vấn đề đó là node chưa tồn tại trong document hiện tại. Do vậy, chúng ta phải thực hiện động tác import node đó vào document hiện tại mà chúng ta đang xây dựng.
Ở đây, để đơn giản cho quá trình ghi file trong bài viết, chúng ta thực hiện tạo một cây DOM sau đó transform thành các file theo trang và loại sản phẩm đã được cung cấp ban đầu. Chúng ta có thể dùng bất cứ cách nào để ghi file tùy thuộc vào tính huống thực tế.
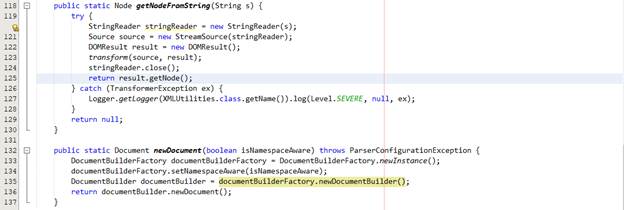
Các hàm hỗ trợ cho quá trình xử lý như chuyển đổi Node thành String và tạo ra Document mới có trong class trên trong XMLUtilities.
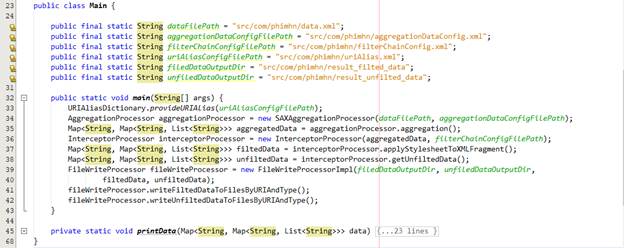
Chúng ta thực hiện thêm vào class Main để chạy thử xem việc ghi ra file có thành công hay không
Chúng ta nhận được kết quả như sau:

Cuối cùng, chúng ta kiểm tra lại hai file để xác nhận kết quả thông qua chức năng search trong tool Netbeans
File
xyz_company.xml
File
xyz_product.xml
Như vậy, chúng ta thấy hai vấn đề ở đầu bài viết đã được ta chia nhỏ ra thành từng nhóm và đưa vào các bộ lọc interceptor để xử lý đồng nhất định dạng cho từng loại dữ liệu từ các trang web khác nhau.
Tổng quan, chúng ta có thể xem quá trính chuyển đổi qua từng giai đoạn của một fragment company của trang xyz.vn như sau:

4. Gom nhóm các thao tác xử lý dữ liệu
Chúng ta nhận thấy các thao tác xử lý dữ liệu vừa rồi mang tính quy trình. Dữ liệu đầu ra của quá trình này là dữ liệu đầu vào của quá trình khác. Từ đó, chúng ta gom các thao tác xử lý dữ liệu trên lại thành một quy trình xử lý. Chúng ta tạo ra một class để gom các xử lý trên như sau:
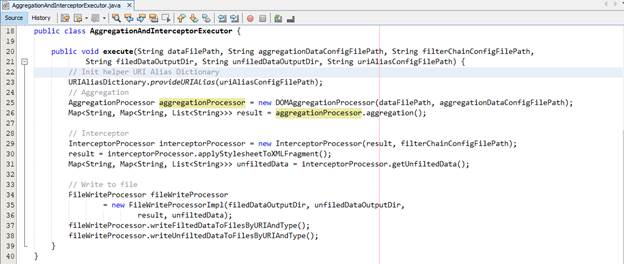
Vậy class Main của chúng ta trở nên gọn gang, súc tích và dễ hiểu như cách trình bày bên dưới:

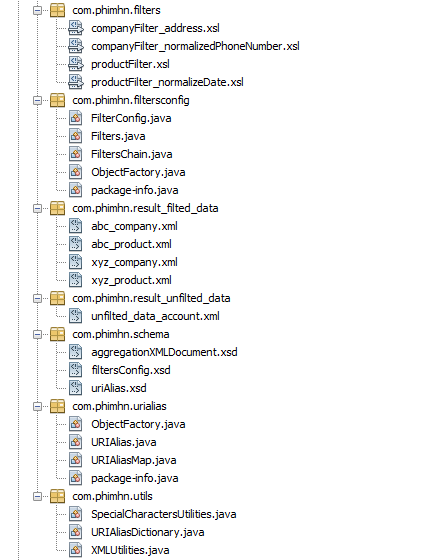
Cấu trúc của project sau khi hoàn thành như sau:

III. Kết luận
Như vậy, chúng ta đã hoàn thành quá trình gom nhóm dữ liệu và tạo ra interceptor cho từng nhóm dữ liệu đi qua để thực hiện lọc cũng như chuẩn hóa dữ liệu. Chúng ta đã thực hiện chia nhỏ một tài liệu xml ra thành các xml fragment sau đó đi qua các interceptors tương ứng và phân bố xử lý lọc dữ liệu ra nhiều file XSL tránh việc một XSL quá lớn, quá phức tạp để lọc dữ liệu. Bài viết có thể xem như một gợi ý cho quá trình xử lý dữ liệu của quí vị. Hy vọng thông qua bài viết, quí vị có thể phát triển tốt quy trình xử lý dữ liệu từ ý tưởng của bài viết.
Qua bài viết, chúng ta cũng thấy được sự uyển chuyển khi kết hợp các thành phần với nhau, gắn kết các thành phần lại thông qua các metadata, việc gom nhóm dữ liệu và phân tán xử lý lọc dữ liệu ra nhiều file xsl. Rất mong quí vị góp ý về nội dung bài viết này.
Không có nhận xét nào:
Đăng nhận xét