Parse tài liệu XML không validation áp dụng cơ chế tiền xử lí và thực hiện chia nhỏ tài liệu phân tích thành các XML fragment
Tác giả: Lê Thanh Nam
Mục đích: Bài viết nhằm hướng dẫn parse và xử lí tài liệu XML chưa well-formed. Một tài liệu XML được xem là lỗi khi không well-formed hoặc không validate. Tuy nhiên các bộ parser có sẵn trong JDK như SAX và StAX không hỗ trợ trong việc xử lí các tài liệu xml không well-formed (SAX kiểm tra well-formed mới xử lý, StAX kiểm tra well-formed từng phần, đa số các trường hợp không đúng chuẩn well-formed sẽ dừng quá trình xử lí). Chúng tôi giới thiệu giải pháp xử lý các vấn đề này thông qua việc hiện thực bộ Resolver nhằm giải quyết trường hợp lỗi well-formed thông dụng nhất như lỗi nested tag (thiếu, thừa thẻ). Bên cạnh đó, chúng tôi sẽ hướng dẫn cách chia tài liệu xml thành nhiều phần nhỏ nhằm giải quyết xử lý các nội dung không well-formed một cách dễ dàng hơn. Giải pháp này sử dụng các bộ parser SAX và StAX kết hợp việc validate dữ liệu sử dụng JAXB kết hợp với bộ Validator.
Yêu cầu:
o Nắm vững khái niệm về XML và cách viết một tài liệu chuẩn well-form (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-inh-nghia-cach-viet.html )
o Có kiến thức về XML Schema (tham khảo thêm bài viết tương ứng tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-schema-inh-nghia-cach.html )
o Nắm vững cách sử dung các bộ StAX Parser (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/10/dung-stax-parser-e-xay-dung-ung-dung.html )
o Nắm vững cách sử dung các bộ SAX Parser (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/10/su-dung-sax-parser-e-tim-kiem-du-lieu.html )
o Nắm vững cách sử dung JAXB (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/10/jaxb-chuyen-oi-xml-schema-hay-dtd-tro.html )
Hiện thực
Tool và các công nghệ sử dụng
· Netbeans 8.1
· JDK 8
· Các bộ parser SAX, StAX
· JAXB
Cấu trúc của tài liệu XML
o Nội dung để minh họa cho ý tưởng xử lý trong bài này định hướng thể hiện thông tin của một thư viện.
· Đối tượng quản lý trong thư viện này là nhân viên và sách.
· Đối tượng nhân viên có 02 thuộc tính là id và tên.
· Đối tượng sách có 4 thuộc tính là id, tên, tác giả, giá tiền.
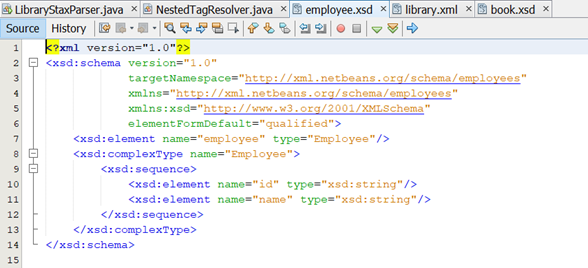
· Tài liệu XML Schema mô tả cấu trúc của Book được thể hiện như hình bên dưới

· Tài liệu XML Schema mô tả cấu trúc của Employee được thể hiện như hình bên dưới
Mục tiêu chính trong việc xử lý định hướng đến các lỗi sau
o Lỗi nested tag, tức là lỗi thừa, thiếu thẻ đóng mở (1)
o Lỗi validate (2)
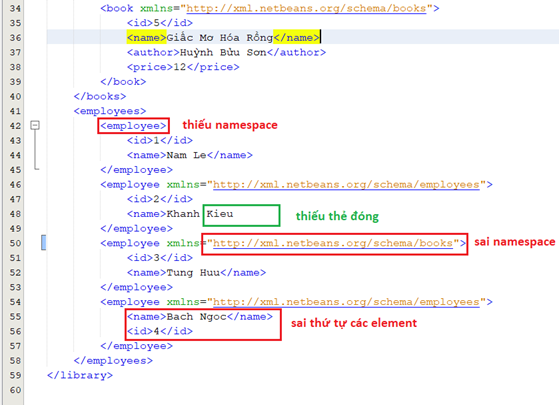
o Tài liệu XML mẫu mô tả các lỗi sẽ được xử lý được mô tả tiếp theo bên dưới

Các bước thực hiện
· Để thuận lợi cho việc xử lý, chúng ta thực hiện chia nhỏ các công việc vào trong các thành phần nhỏ hơn được thể hiện theo các thành phần chức năng như sau
o LibraryStaxParser: Thực hiện parse tài liệu xml và chia nhỏ tài liệu thành các fragment có cấu trúc xml đơn giản nhất trong quá trình xử lý.
o NestedTagResolver: Thực hiện tiền xử lý lỗi nested tag.
o SchemaValidator: Thực hiện validate dữ liệu theo schema cấu trúc cho từng đối tượng trong ứng dụng
o StreamExceptionHandler: Thực hiện xử lý lỗi cơ bản trong quá trình parse dữ liệu
o SAXErrorDataParser: Thực hiện xử lý lỗi trong quá trình xử lý dữ liệu
· Cấu trúc tổ chức project đề xuất như hình bên dưới

1. Sử dụng resolver để xử lý dữ liệu đầu vào trước khi parse XML
o Bộ resolver thực hiện công việc tiền xử lí dữ liệu trước khi parse. Sau khi qua được resolver thì kết quả chúng ta sẽ có một xml đầy đủ thẻ mở, thẻ đóng, có duy nhất một root, và được loại bỏ hoàn toàn các thẻ XML declaration và comment.
o Các bước thực hiện
· Thực hiện cắt tài liệu XML trở thành các phần đơn giản nhất có thể xử lý
§ Giải pháp của việc này là chúng ta tiến hành cắt dữ liệu thành các chuỗi, mỗi chuỗi có thể chứa: thẻ mở, thẻ đóng hoặc chuỗi kí tự.
§ Comment sẽ được loại bỏ trong quá trình này.
§ Output của phương thức này là danh sách các chuỗi.
§ Lưu ý là phương thức này chưa thể nhận biết CDATA, XML Declaration, quí vị có thể tự bổ sung để nâng cấp việc xử lý
· Chúng ta hiện thực nội dung này thông qua phương thức splitXMLDocument
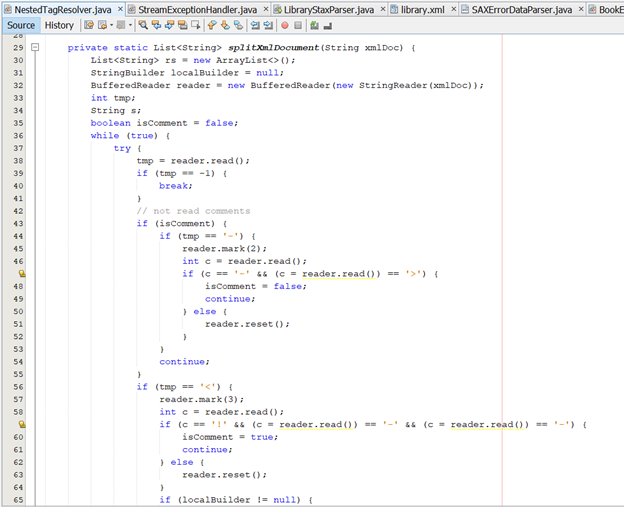

§ Trong quá trình implement ở trên, chúng ta sử dụng class BufferedReader để biến chuỗi thành stream.
· Việc sử dụng BufferedReader sẽ hỗ trợ hàm mark(int readAheadLimit) và reset() (Hai hàm này được sử dụng ở dòng 45,51 và 57,63)
· Hàm mark() sẽ đánh dấu vị trí hiện tại trong stream, tham số truyền vào là giới hạn số lượng kí tự có thể đọc kể từ vị trí đánh dấu.
· Cụ thể của giải pháp này là BufferedReader sẽ cấp phát 1 buffer có độ lớn bằng với giá trị truyền vào để lưu các giá trị được đọc khi gọi hàm next(). Hàm reset() sẽ quay ngược trở về vị trí đã được đánh dấu (nếu có). Điều này là cần thiết khi chúng ta gặp kí tự ‘<’, ta gọi mark() để đánh dấu vị trí hiện tại rồi kiểm tra 3 kí tự tiếp theo có phải là chuỗi “!--” hay không.
o Nếu đúng, thì chúng ta đang gặp phải 1 comment, và cờ isComment được kích hoạt, các giá trị tiếp theo sẽ được bỏ qua đến khi ra khỏi 1 comment.
o Nếu sai, chúng ta trở về vị trí được đánh dấu bằng cách gọi reset(). Điều này cũng tương tự với sự kiện kết thúc comment.
· Chúng ta tiếp tục kiểm tra một chuỗi là start element, end element, characters, hay XML declaration thông qua phương thức checkTagType bên dưới

· Để lấy được cụ thể thẻ tag nào đang được xử lý, chúng ta xây dựng phương thức để đọc tag name thông qua phương thức getLocalName

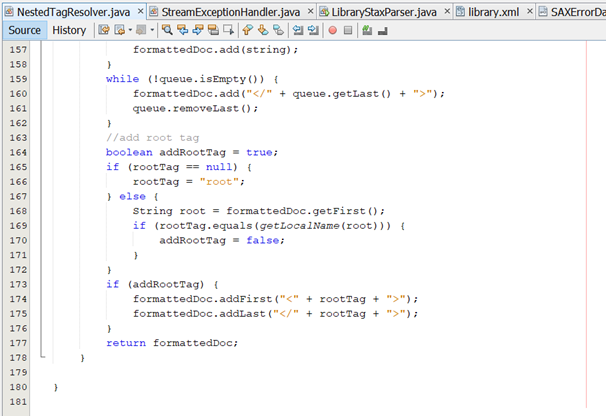
· Tiếp theo, chúng ta chuẩn hóa nội dung của các thành phần XML
§ Input của phương thức này là một chuỗi tài liệu xml và giá trị của root tag của tài liệu.
§ Tài liệu sau xử lý nếu có root tag sai sẽ được thêm root tag cho đúng.
§ Output của method này là List<String> chứ không phải là String đơn thuần (mỗi String là 1 thẻ, hoặc chuỗi giữa các thẻ).

· Chúng ta vừa hoàn tất việc xử lý đầu vào để có một tập các thành phần XML đơn giản chuẩn bị cho việc xử lý
2. Sử dụng StAX để chia nhỏ tài liệu thành các fragment
o Sau khi đã xử lý dữ liệu đầu vào, chúng ta áp dụng StAX để chia nhỏ tài liệu XML thành các phần nhỏ hơn. Cụ thể, từ tập tin xml (trong bài viết này là file library.xml), chúng ta sẽ parse thành các fragment có root là <book> hoặc <employee>.
o Việc tách tài liệu thành các thành phần nhỏ hơn sẽ hỗ trợ chúng ta trong việc kiểm tra lẫn xử lý.
o Trong trường hợp fragment không validate, chúng ta vẫn có thể sử dụng bộ parse đặc biệt để lọc ra tập dữ liệu lỗi.
o Method parse() là phương thức để thực hiện chia nhỏ dữ liệu và validate dữ liệu cùng với việc xử lý dữ liệu không validate.
o Các bước thực hiện
· Chúng ta tạo các biến dùng chung hỗ trợ trong việc xử lý

§ Biến bookRs và employeeRs sẽ chứa phần dữ liệu validate
§ Biến bookErrRs và employeeErrRs sẽ chứa phần dữ liệu không validate.
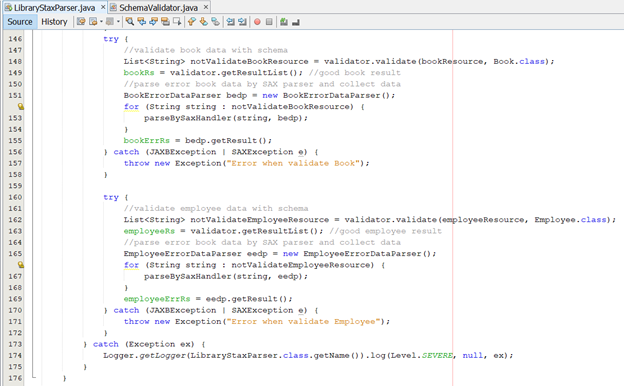
· Cài đặt hàm parse để thực hiện giải pháp đã nêu ở trên:
§ Ở đây, chúng ta áp dụng schema Validator để thực hiện validate dữ liệu dựa trên qui định của schema
· Đối tượng Schema Validator sẽ được mô tả trong phần mục 3 của nội dung bài này bên dưới
§ Chúng ta thực hiện cài đặt hàm parse
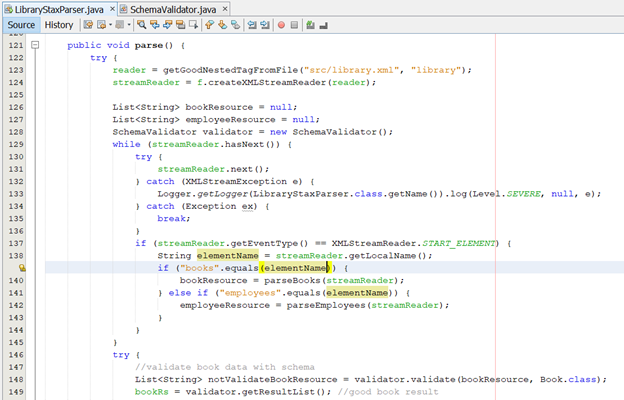
§ bookResource trong đoạn code nêu trên chứa các fragment có root là <book>
§ employeeResource chứa các fragment có root là <employee>
§ Khi StreamReader đọc tới thẻ <books>, nó bắt đầu parse thành các book fragment, tương tự khi đọc tới thẻ <employees> sẽ chuyển thành các employee fragment
§ Trong đoạn code nêu trên thì hàm getGoodNestedFromFile được implement như hình bên dưới
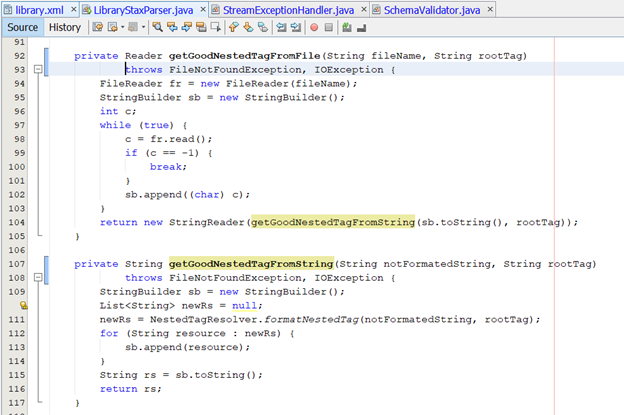
· Hàm getGoodNestedTagFromFile() sẽ thực hiện đọc file, gọi đến hàm getGoodNestedTagFromString() để thực hiện tiền xử lí và sau đó trả về 1 StringReader dùng để đọc tài liệu XML đã được xử lí.
· Hàm getGoodNestedTagFromString() sẽ gọi đến bộ NestedTagResolver đã được đề cập ở trên để thực hiện tiền xử lí cho tài liệu XML. Sau quá trình tiền xử lí nó sẽ ghép tất cả các String trong danh sách được trả về bởi NestedTagResolver thành 1 chuỗi và trả về.
· Việc cài đặt đối tương BookErrorDataParser, EmployeeErrorDataParser sẽ được mô tả trong phần 4 bên dưới của nội dung bài này
· Việc cài đặt hàm parseBySaxHandler sẽ được mô tả vào cuối phần mục 4 bên dưới nội dung bài viết này
· Tiếp theo chúng ta cài đặt các method dùng để phân tách fragment. Mỗi đối tượng trong library sẽ có 1 hàm parse tương ứng với từng đối tượng.
§ Cài đặt 2 hàm parseBooks() và parseEmployee()

2 hàm này đều nhận giá trị truyền vào là 1 XMLStreamReader, sau đó gọi tới hàm getXmlFragments() để lấy kết quả là 1 List có kiểu generic là List<XMLEvent>.
· Với đối tượng book, bộ parse sẽ hiểu root của mỗi fragment là thẻ <book> và sẽ kết thúc quá trình parse fragment khi gặp thẻ đóng chứa các fragment đó là thẻ <books>. Tương tự với đối tượng employee.
· Mỗi đối tượng List<XMLEvent> là danh sách các element của 1 fragment book hoặc employee. Với mỗi đối tượng List<XMLEvent> sẽ được convert thành 1 String. Hàm convertEventListToStringList() sẽ thực hiện chuyển đổi kiểu List<List<XMLEvent>> thành kiểu List<String>.
· Code cài đặt hàm convertEventListToStringList():

Hàm này sẽ gọi đến hàm convertXmlEventToString() để chuyển kiểu List<XMLEvent> thành kiểu String.
§ Tiếp theo ta cài đặt hàm getXmlFragments:
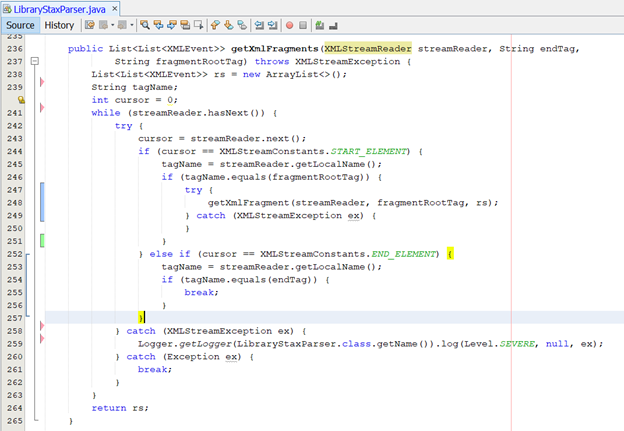
Hàm này nhận input là 1 XMLStreamReader, fragmentRootTag là tên của thẻ root của các fragment, endTag là tên của thẻ chứa các fragment đó.
· Biến rs là danh sách kết quả trả về
· Khi gặp thẻ mở có tên trùng với fragmentRootTag thì sẽ gọi tới hàm getXmlFragment() để bắt đầu thực hiện parse fragment.
· Việc parse sẽ kết thúc khi bộ parser gặp thẻ đóng trùng với endTag.
§ Ta tiếp tục cài đặt hàm getXmlFragment():

Hàm này có nhiệm vụ parse các fragment. Input gôm XMLStreamReader, rootTag chứa tên root fragment, rs là danh sách chứa kết quả trả về. Các fragment được parse sẽ tiếp tục được thêm vào danh sách này.
· Mỗi khi gặp 1 thẻ mở có tên giống rootTag, ví dụ là <book>, bộ parser sẽ hiểu là đã kết thúc fragment hiện tại và dừng quá trình parse fragment.
· Nếu fragment chưa có thẻ đóng nó sẽ gọi tới hàm newEndElement() để thêm thẻ đóng cho fragment đó. Hàm newEndElement() có trong class StreamExceptionHandler.
· Ta bắt đầu cài đặt class StreamExceptionHandler:
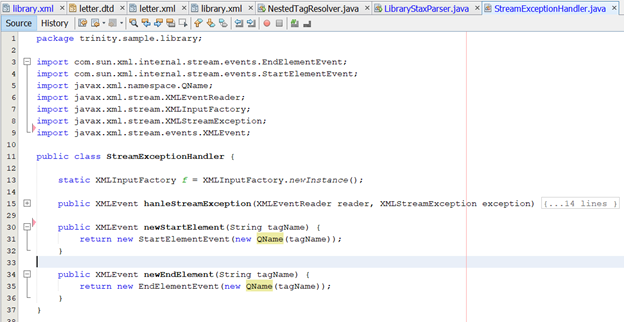
· Class này có 2 hàm chính là newStartElement() để tạo 1 XMLEvent thẻ mở, newEndElement() đê tạo 1 XMLEvent thẻ đóng.
3. Validate các fragment bằng JAXB
o Sau khi đã chia nhỏ dữ liệu thành các fragment, chúng ta tiến hành validate các fragment với Schema tương ứng.
· Book fragment sẽ được validate bằng book.xsd
· Employee fragment sẽ được validate bằng employee.xsd.
o Đầu tiên, chúng ta cần mapping object và schema bằng JAXB
· Sử dụng tính năng JAXB binding của Netbeans để generate JAXB object từ Schema


§ Kết quả phát sinh chúng ta sẽ có cấu trúc như bên dưới trong generated resource:

o Tiếp theo, chúng ta xây dựng class dùng để validate dữ liệu
· Bắt đầu cài đặt class SchemaValidator dùng để validate XML fragment

§ Biến resultList dùng để chứa danh sách object được parse từ các validate fragment.
§ Hàm getSchemaLocation() sẽ trả về đường dẫn của XML schema tương ứng với các JAXB object. Nếu không tìm thấy nó sẽ ném ra một RuntimeException dừng quá trình validate ngay lập tức.
§ Chúng ta thực hiện cài đặt hàm validate() dùng để validate và transform XML fragment thành object:

· Method validate() nhận vào 1 danh sách các XML fragment, kiểu JAXB object và trả về 1 danh sách các fragment không validate. Các fragment validate sẽ được parse thành JAXB object chứa trong biến resultList.
· Khi validate fragment ở dòng 59, hoặc khi unmarshal ở dòng 60 bị lỗi, fragment đó sẽ được hiểu là fragment không validate và được thêm vào danh sách kết quả trả về.
4. Parse dữ liệu không validate bằng SAX parser
o Các fragment không validate có thể có nhiều nguyên nhân. Có thể là vì sai thứ tự element, sai kiểu dữ liệu, thiếu element, sai/thiếu namespace,.v.v. Những dữ liệu vẫn hữu dụng cho nên chúng ta có thể ghi nhận để sử dụng.
· Chúng ta dùng SAX để làm điều này vì tài liệu XML hiện tại là các fragment đã well-formed và có cấu trúc đơn giản.
· Chúng ta hiện thực các bộ xử lý cho từng loại fragment khác nhau.
§ Việc xây dựng các class này sẽ thừa kế từ DefaultHandler.
§ Chúng ta chỉ quan tâm tới 3 event chính là startElement(), endElement() và characters().
§ Tất cả các class này, chúng ta đều implement interface SAXErrorDataParser, có method getResult() nhằm lấy ra các Object đã parse được.
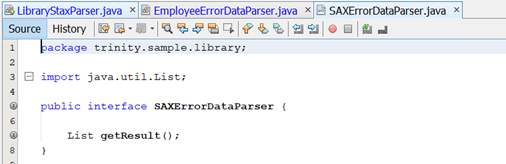
§ Chúng ta viết code cho book fragment:

· Các giá trị của trong quá trình parse sẽ được lưu tạm ở các biến id, name, author, price.
· Hàm reset() sẽ set lại giá trị mặc định cho các biến tạm.
· Hàm startElement() được gọi mỗi khi gặp thẻ mở. Khi gặp thẻ <book> thì cờ found sẽ được bật lên, cho biết là đang ở trong book fragment. Sau đó nó set tên của tag hiện tại vào biến currentTagName.

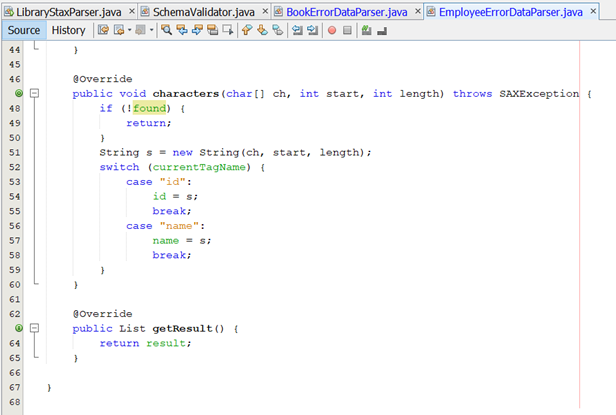
· Hàm characters() được gọi mỗi khi gặp kí tự giữa thẻ, nếu cờ found được bật, nó sẽ map các thẻ với các biến tương ứng.
· Hàm endElement() được gọi mỗi khi gặp thẻ đóng. Khi gặp thẻ <book>, parser hiểu là đã kết thúc fragment, tạo mới object book, set giá trị và thêm vào danh sách kết quả. Sau đó nó gọi hàm reset để trả về giá trị mặc định cho các biến tạm.
§ Tương tự, chúng ta viết class xử lý cho employee fragment:

§ Chúng ta tiếp tục bổ sung method parseBySaxHandler() của LibraryStaxParser

· Hàm này nhận vào 1 chuỗi XML fragment và 1 DefaultHandler dùng để parse cho chính fragment đó.
· Để parse fragment ta khởi tạo 1 SAXParser và gọi hàm parse để parse fragment. Hàm parse yêu cầu 1 InputSource và 1 DefaultHandler (dòng 175).
· Chúng ta có thể tạo ra object InputSource bằng cách gọi hàm createInputSource của class SchemaValidator.
5. Chúng ta tiến hành chạy để kiểm thử kết quả của chúng ta xử lý ở trên
o Chúng ta thực hiện cài đặt hàm main như bên dưới

o Chúng ta thực hiện chạy thử, Chúng ta có kết quả:

6. Tổng kết
o Như vậy, với input là 1 tài liệu XML không well-formed và validate, chúng ta thực hiện xử lí thông qua 4 bước:
1. Xử lí input với bộ resolver
2. Sử dụng StAX để chia nhỏ tài liệu thành các fragment
3. Validate các fragment bằng JAXB
4. Parse dữ liệu không validate bằng SAX parser
· Kết quả cuối cùng của việc xử lý này là chúng ta có các tập dữ liệu validate và các tập dữ liệu không validate.
· Đối với các tập dữ liệu không validate, chúng ta có thể sử dụng thêm 1 số bước xử lí nữa để có thể trở thành dữ liệu validate.
o Bước quan trọng nhất trong quá trình này là bước số (2).
· Việc chia tài liệu XML thành các fragment giúp cho việc parse dữ liệu được tối ưu. Vì sau khi trải qua xử lí well-formed, tài liệu có thể đã mất đi cấu trúc ban đầu của nó.
· Do vậy, trường hợp này nếu validate ngay tài liệu bằng schema chắc chắn sẽ không validate. Và nếu có viết 1 bộ parse dữ liệu lỗi thì sẽ rất tốn công vì có quá nhiều trường hợp nảy sinh.
· Việc chia nhỏ tài liệu cũng giúp cho schema trở nên đơn giản hơn.
Rất mong bài viết này sẽ hỗ trợ cho quý vị trong việc xử lý và crawl dữ liệu. Rất mong đóng góp của quí vị về nội dung này
Không có nhận xét nào:
Đăng nhận xét