Trích xuất dữ liệu theo phương pháp tận dụng chức năng tìm kiếm của website đang trích xuất và một số kỹ thuật hỗ trợ tiền xử lý và đồng bộ dữ liệu được trích xuất vào bộ lưu trữ
Tác giả: Lê Hùng Sơn
Mục đích:
Bài viết cung cấp phương pháp tiếp cận về trích xuất dữ liệu trên các website bằng cách tận dụng bộ tìm kiếm sẵn trên các trang đang xử lý. Đây là ý tưởng có thể ứng dụng cho trang web sử dụng kỹ thuật động mà không cần sử dụng các framework. Ở đây, chúng tôi sẽ xử lý trang diadiemanuong và foody như là trường hợp áp dụng cho việc lấy danh mục dữ liệu và lấy thông tin ở một trang khác.
Bên cạnh đó, chúng tôi giới thiệu một số kỹ thuật hỗ trợ trong việc tiền xử lý dữ liệu sau khi trích xuất và đồng bộ dữ liệu đã được xử lý xuống bộ lưu trữ với mục đích hỗ trợ truy xuất dữ liệu một cách hiệu quả. Trong bài này, chúng tôi sử dụng bộ StAX parser kết hợp JAXB để trích xuất khai thác và đồng bộ dữ liệu.
Yêu cầu kiến thức cơ bản:
· Nắm vững khái niệm về ngôn ngữ lập trình Java, lập trình thao tác hướng đối tượng và các thành phần liên quan
· Nắm vững khái niệm về XML và cách viết một tài liệu chuẩn well-form (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/08/gioi-thieu-ve-xml-inh-nghia-cach-viet.html )
· Nắm vững cách sử dung các bộ Parser, cụ thể ở đây là bộ StAX (tham khảo bài viết tại địa chỉ http://www.kieutrongkhanh.net/2016/10/dung-stax-parser-e-xay-dung-ung-dung.html )
· Nắm vững khái niệm về JAXB, cách tạo JAXB Object (tham khảo tại địa chỉ http://www.kieutrongkhanh.net/2016/10/jaxb-chuyen-oi-xml-schema-hay-dtd-tro.html ).
· Biết cách xây dựng một ứng dụng JavaEE, kết nối với hệ quản trị cơ sở dữ liệu sử dụng JDBC.
Công cụ yêu cầu:
· Netbeans IDE 8.1
· Tomcat server 8.x
· SQL Server Management Studio
Giới thiệu cấu trúc của project
Để tiện việc theo dõi, trước tiên tôi giới thiệu cấu trúc các class và package sẽ dùng trong bài viết:

Phần 1: Các kỹ thuật hỗ trợ
· Chúng ta sẽ thực hiện tạo class utilities có tên CrawlHelper để thực hiện implement các nội dung kỹ thuật mô tả tiếp theo để hỗ trợ xử lý dữ liệu. Trong class chia làm 3 phần tương ứng là 3 kỹ thuật chính sẽ đề cập trong bài này: LCS, Stack, Hashing

Tính toán độ giống giữa hai chuỗi (LCS)
Yêu cầu
Với hai chuỗi ![]() và
và ![]() tương đồng
giữa hai chuỗi.
tương đồng
giữa hai chuỗi.
Phương pháp
· Gọi
![]() độ dài chuỗi
con chung dài nhất hai chuỗi khi xét
độ dài chuỗi
con chung dài nhất hai chuỗi khi xét ![]() ký tự đầu
của chuỗi
ký tự đầu
của chuỗi ![]() và
và ![]() kí tự đầu
của chuỗi
kí tự đầu
của chuỗi ![]() .
.
·
Kết
quả chính là ![]() .
.
·
![]()
![]()
· Ngược
lại: ![]()
Implementation:
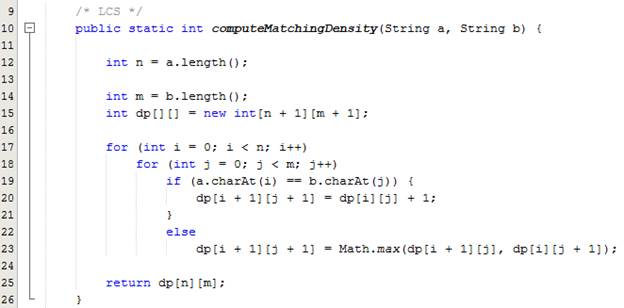
Ví dụ:
![]()
![]()
![]()
Từ kết quả trên, chúng ta có thể tính độ giống của hai dữ liệu trên là:
· ![]()
Ứng dụng:
1. Kiểm tra dữ liệu đang xử lý có tồn tại trong bộ dữ liệu nhằm hạn chế tránh trùng lắp/ dư thừa dữ liệu
2. Dựa vào tỉ lệ tương đồng giữa hai chuỗi, chúng ta có thể đặt một cận với ý nghĩa: nếu hai chuỗi giống nhau trên bao nhiêu phần trăm thì cho rằng đó là dữ liệu trùng lắp.
3. Hỗ trợ xây dựng nâng cao cho bộ tìm kiếm: chúng ta có thể dùng để tìm kiếm keyword gần đúng hoặc gợi ý từ khóa cho người dùng.
Ví dụ: ứng dụng cho việc gợi ý các nội dung tương ứng khi nhập từ khóa có chứa một phần nội dung cần tìm kiếm

Nguồn tham khảo:
https://en.wikipedia.org/wiki/Longest_common_subsequence_problem
https://www.geeksforgeeks.org/longest-common-subsequence/
Kỹ thuật dùng ngăn xếp (Stack) để well-form dữ liệu
Chúng tôi trình bày phương pháp này với mục đích thực hiện well-form tài liệu html nhằm hoàn thiện cấu trúc tổ chức dữ liệu của một định dạng dành cho việc trình bày dữ liệu hơn là khai thác dữ liệu trước khi đưa vào bộ Parser. Phương pháp ở đây sẽ áp dụng cách tổ chức của cấu trúc dữ liệu là ngăn xếp (Stack).
Ưu điểm
- Hỗ trợ chúng ta trong cách chỉnh sửa dữ liệu tổng quát mà không cần quan tâm bản chất các thẻ thiếu trong dữ liệu có ngữ nghĩa cụ thể là như thế nào.
- Không quá phức tạp để có thể cài đặt.
- Độ phức tạp thuật toán là tuyến tính vì tài liệu chỉ duyệt qua một lần.
Nhược điểm
- Xử lý tốn nhiều thời gian vì phải xét hết tất cả dữ liệu đang xử lý (vét cạn).
Các kiến thức cơ bản về stack
- Stack là một cấu trúc dữ liệu động (dynamic data structures) và vận hành với nguyên lí Last In First Out (LIFO) - phần tử nào thêm vào cuối thì sẽ bị xóa đầu tiên.
- Nhờ cơ chế LIFO nên người ta thường dùng stack để kiểm tra các dãy ngoặc đúng, tổ chức các hàm đệ quy, một số cách tổ chức lưu trữ trong hệ điều hành,…
- Hai thao tác chính của stack là push – thêm một phần tử vào cuối stack và pop – xóa phần tử ở cuối ngăn xếp.
Ý tưởng
- Duyệt chuỗi từ trái qua phải, nếu gặp một thẻ mở thì đưa thẻ đó vào stack.
- Nếu gặp thẻ đóng, kiểm tra xem ở cuối stack đó có thẻ mở ứng với nó không.
o Nếu không thì thẻ mở hiện tại ở cuối stack đang bị thiếu thẻ đóng => chúng ta tiến hành đóng thẻ đó.
o Nếu gặp thẻ mở tương ứng với thẻ đóng ở cuối ngăn xếp thì chúng ta chỉ việc loại bỏ thẻ mở đó ra khỏi ngăn xếp.
- Khi tiến trình kết thúc, nếu ngăn xếp vẫn còn các thẻ mở, chúng ta tiến hành đóng tuần tự: lấy từ cuối ngăn xếp ra, thêm thẻ đóng ứng với nó và loại bỏ nó ra khỏi stack. Lặp lại đến khi stack rỗng.
- Chuỗi well-form yêu cầu phải cần một root element, một số tài liệu sẽ bị thiếu root nên chúng ta thực hiện việc thêm một thẻ lớn để bọc ngoài
o
Ví
dụ: ![]()
Implementation
Đầu tiên, chúng ta tạo một phương thức xác định tên của thẻ cùng với xác định thẻ mở hay thẻ đóng

· Những thẻ đóng sẵn như <input/> <br/> thì ta bỏ qua, trả về null.
· Các thẻ mở <div>, <img> thì trả về tên thẻ là: div, img
· Các thẻ đóng </h3>, </span>, … thì trả về tên thẻ và dấu đóng ở trước: /h3, /span
Tiếp theo, chúng ta thực hiện xây dựng phương thức chỉnh sửa những thành phần thẻ sai định dạng well-formed
· Khởi tạo:

o
![]() : thành phần quan
trọng nhất của thuật toán được dùng để
lưu trữ danh sách các chuỗi thẻ mở
: thành phần quan
trọng nhất của thuật toán được dùng để
lưu trữ danh sách các chuỗi thẻ mở
o
![]() : danh sách song song với
stack, mỗi vị trí thẻ mở bỏ vào chúng ta phải
lưu lại vị trí ngay sau thẻ đó để sau
này nếu cần thì đó là vị trí để thêm thẻ
đóng vào.
: danh sách song song với
stack, mỗi vị trí thẻ mở bỏ vào chúng ta phải
lưu lại vị trí ngay sau thẻ đó để sau
này nếu cần thì đó là vị trí để thêm thẻ
đóng vào.
o
![]() : danh sách các thẻ
phải bổ sung vào để tài liệu thành well-form
: danh sách các thẻ
phải bổ sung vào để tài liệu thành well-form
o
![]() : mảng đánh dấu
với ý nghĩa:
: mảng đánh dấu
với ý nghĩa: ![]() khác
khác ![]() tức là phải
thêm thẻ đóng vào sau ký tự thứ
tức là phải
thêm thẻ đóng vào sau ký tự thứ ![]() , và thông tin thẻ
đóng này chính là
, và thông tin thẻ
đóng này chính là ![]() .
.
o Khởi tạo một biến con trỏ đứng ở đầu chuỗi và lặp đến cuối chuỗi:
![]()
· Xử lý
o Nếu gặp kí tự mở ngoặc thì lấy hết toàn bộ các ký tự bên trong thẻ (tên thẻ) cho đến khi gặp thẻ đóng.

o
Nếu
![]() đang xét là một
thẻ đúng thì có hai trường hợp:
đang xét là một
thẻ đúng thì có hai trường hợp:
1.
Tag
là thẻ mở: thêm thẻ đó cùng với vị trí kết
thúc đóng thẻ vào ![]() và
và ![]() .
.
2. Tag là thẻ đóng:
a.
Nếu
thẻ đóng đó giống với thẻ mở đang ở
cuối ngăn xếp => loại bỏ thẻ đó ra
khỏi ngăn xếp. Lưu ý khi bỏ phần tử
của ![]() thì phải bỏ
tương ứng ở danh sách
thì phải bỏ
tương ứng ở danh sách ![]() .
.
b.
Ngược
lại, chúng ta đánh dấu là thẻ cuối stack đang
thiếu thẻ đóng, lưu thông tin sửa vào ![]() và mảng
và mảng ![]() .
Sau đó xóa phần tử cuối ngăn xếp đi. Quá
trình này lặp lại cho đến khi thẻ đóng tìm
được thẻ mở của nó.
.
Sau đó xóa phần tử cuối ngăn xếp đi. Quá
trình này lặp lại cho đến khi thẻ đóng tìm
được thẻ mở của nó.

o
Và
thực hiện tăng biến ![]() lên khi nó không phải
là dấu hiệu mở thẻ:
lên khi nó không phải
là dấu hiệu mở thẻ:

o Cuối cùng, khi ngăn xếp vẫn còn phần tử thì lấy lần lượt từ cuối ngăn xếp về đầu, các thẻ này ta phải đóng để dữ liệu được chuẩn well-form do đó cũng lưu thông tin sửa vào addTag và mảng mark.

o
Sau
khi có toàn bộ thông tin của nội dung đang xử lý, chúng
ta tiến hành sửa lại các tag cho tài liệu. Dựa
vào mảng ![]() và danh sách
và danh sách ![]() để thêm các
tag đóng vào vị trí thích hợp.
để thêm các
tag đóng vào vị trí thích hợp.
o Thêm root element và trả về nội dung đã được sửa.

· Testing: thực hiện viết code để kiểm tra hàm cài đặt có hoạt động tốt không bằng cách tạo một Java class với hàm main để testing

§ Thực thi class này, chúng ta sẽ nhận được kết quả như sau

Lưu ý:
- Dùng stack là làm cách tổng quát để chỉnh well-form dữ liệu. Tuy nhiêu, nếu số lượng sai sót không quá nhiều thì chúng ta nên cân nhắc thực hiện trực tiếp với hard code trong quá trình xử lý để nhằm cải tiến tốc độ parse dữ liệu cho ứng dụng
- Ví
dụ tài liệu chỉ thiếu mỗi thẻ đóng ![]() , chúng ta có thể
chỉ cần tìm thẻ img và sửa mà không cần áp dụng
nguyên bộ stack. Việc này có thể thực hiện bằng
cách viết hard code trực tiếp với việc khi thấy
thẻ img thì tìm đến cuối và bổ sung thẻ
</img> nếu thẻ đóng này không tồn tại
, chúng ta có thể
chỉ cần tìm thẻ img và sửa mà không cần áp dụng
nguyên bộ stack. Việc này có thể thực hiện bằng
cách viết hard code trực tiếp với việc khi thấy
thẻ img thì tìm đến cuối và bổ sung thẻ
</img> nếu thẻ đóng này không tồn tại
Nguồn tham khảo:
https://www.geeksforgeeks.org/stack-data-structure-introduction-program/
https://www.hackerearth.com/fr/practice/data-structures/stacks/basics-of-stacks/tutorial/
https://www.topcoder.com/community/data-science/data-science-tutorials/data-structures/
Kỹ thuật hashing để kiểm tra tính tồn tại dữ liệu
Tại sao dùng hashing?
Việc cào dữ liệu xảy ra định kỳ nhưng không phải tất cả dữ liệu khi cào về đều là dữ liệu mới. Chúng ta cần có một cách để kiểm tra xem dữ liệu có trùng lắp với dữ liệu đang có trong bộ lưu trữ. Hashing là một phương pháp đơn giản nhưng vô cùng hiệu quả để giải quyết vấn đề nêu trên.
Việc hash các keyword từ chuỗi thành một số nguyên giúp tăng tốc khả năng kiểm tra trùng khi làm với database vì so sánh số lúc nào cũng nhanh hơn.
Cài đặt một bộ hash chuỗi giản đơn
Ta cần:
- MOD: hằng số mod, là miền giá trị mà khi ta hash chuỗi.
- BASE: là hệ số hash, có thể chọn một số ngẫu nhiên nhưng tốt nhất là nên dùng một số nguyên tố để tối thiểu hóa trường hợp conflict (hash hai chuỗi khác nhau ra giá trị giống nhau) xảy ra.
Ở đây chúng ta sẽ chọn: MOD=10^9 + 7 (một số đủ lớn) và BASE là số nguyên tố 30757.

Nguồn tham khảo:
http://vnoi.info/wiki/algo/string/hash
Chúng ta về cơ bản đã có các công cụ để hỗ trợ để tiền xử lý dữ liệu, khai thác dữ liệu trong quá trình thực hiện ứng dụng.
Trước khi vào nội dung chính, tôi trình bày thêm một số chức năng sẽ hỗ trợ thêm trong quá trình xử lý được xây dựng thành một class utilities với tên gọi là StringHelper.

Hàm toRawString mục đích bỏ dấu tiếng Việt và chuyển qua chữ thường. Tôi dùng một HashMap để thay thế các chữ có dấu thành không dấu.
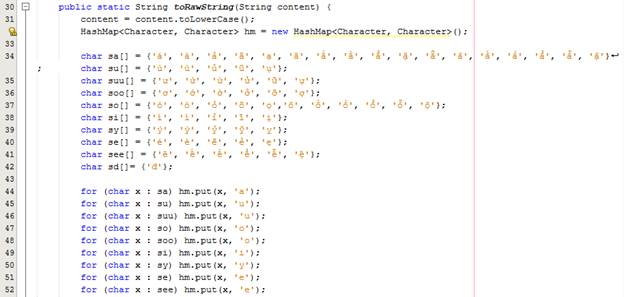

Hàm
![]() :
:
· Mục đính chính là muốn mã hóa chuỗi address thành các block để tiện cho việc so sánh sau này.
· Cú pháp: <số đường>;<tên đường>;<phường>;<quận>
· Ví dụ:
76 Lê Lai, P. Bến Thành, Q.1, Hồ Chí Minh,
Việt Nam è ![]()

Phần 2: Cách thức trích xuất dữ liệu
Trích xuất dữ liệu kết hợp giữa diadiemanuong.com và foody.vn
Ý tưởng dự án:
Thu thập thông tin các quán cà phê, trà sữa trên địa bàn thành phố Hồ Chí Minh. Mỗi quán cần có thông tin địa chỉ và một tập các bình luận về quán.
Có hai trang nổi tiếng để tìm thông tin về các địa điểm này là diadiemanuong.com và foody.vn. Toàn bộ nội dung của bài sẽ hướng tới việc trích xuất dữ liệu trên hai trang này.
Phân tích:
Tất cả thông tin, chúng ta có thể lấy ngay trên foody.vn nhưng việc trình bày dữ liệu trên foody đã được lập trình để không load hết một lượt. Do đó, nếu chúng ta thực hiện việc cào dữ liệu bằng đọc source html thì chúng ta thu thập được lượng dữ liệu rất ít.

Nếu chúng ta sử dụng bộ search bên diadiemanuong, chúngta sẽ nhận được một lượng kết quả lớn (~2000 kết quả).
Bộ search của diadiemanuong:

Trong hình vẽ nêu trên, chúng ta sẽ chọn tất cả các quận. Ở phần loại món, chúng ta sẽ chọn cà phê và trà sữa:

Sau đó, chúng ta nhấn lọc kết quả:

Từ
các nội dung đề cập nêu trên, chúng ta thực hiện
ý tưởng đó là: lấy tên các quán cào được ở
trang ![]() ráp vào bộ search
của
ráp vào bộ search
của ![]() .
.
Tuy nhiên, việc sử dụng bộ search chưa chắc thu nhận được kết quả với đầy đủ thông tin của các quán như chúng ta mong muốn. Do đó, chúng ta sẽ phải kiểm tra kết quả search để thu nhận được các dữ liệu chúng ta cần để lưu trữ và xử lý.
Nếu kết quả đúng như chúng ta mong đợi thì chúng ta sẽ dựa trên thông tin thu thập để lấy ra các bình luận:

Để thực hiện các nội dung phân tích nêu trên, chúng ta thực hiện tuần tự các bước sau
· Bước 1: Chuẩn bị CSDL – DB và JAXB Object
o Tạo JAXB Object để xử lý thông tin liên quan
§ Xử lý thông tin đến quán – ShopInfo có thông tin cấu trúc như sau


§ Xử lý danh sách các quán – ShopList

§ Xử lý các Comment


§ Hỗ trợ thu thập một tập các comment - ListComment

o Cấu trúc database để lưu trữ nội dung kết quả xử lý
§ Bảng dbo.comment

§ Bảng dbo.shop

o Các class hỗ trợ khác:
§ Class: ShopDAO – thao tác với bảng dbo.shop ở Database

Chúng ta sẽ để khóa chính của mỗi shop là một số nguyên tự tăng. Tuy nhiên, chúng ta cần phải lưu thêm bình luận thuộc shop dựa vào khóa chính này. Câu hỏi đặt ra ở đây “Làm cách nào tìm được shop của chúng ta đang xử lý?”
Cách thực hiện như sau: chúng ta thêm một cờ Statement.RETURN_GENERATED_KEYS vào trong hàm khởi tạo preparedStatement. Giá trị khóa tự tăng khi thêm mới shop sẽ được DB trả về trong tập kết quả. Chúng ta dùng hàm getGeneratedKeys để lấy giá trị này. Sau đó, chúng ta chỉ cần getInt(1) là sẽ lấy được giá trị của shop cần tìm.
Với mỗi shop, chúng tôi sẽ lưu giá trị hash của chuỗi kết hợp giữa tên shop (đã bỏ dấu sử dụng hàm toRawString) và địa chỉ shop (đã qua chuẩn hóa sử dụng hàm encodeAdress).
Tiếp theo, chúng ta hiện thực việc kiếm
tra xem shop có chưa bằng cách truyền vào giá trị hash. Nếu
hàm trả về ![]() nghĩa là
shop không tồn và nếu hàm trả về ID nghĩa là quán đã
tồn tại trong DB.
nghĩa là
shop không tồn và nếu hàm trả về ID nghĩa là quán đã
tồn tại trong DB.

§ Class: CommentDAO – thao tác với bảng dbo.comment ở Database

Đối với bình luận, chúng ta sẽ lưu giá trị hash theo nội dung bình luận và người thực hiện bình luận đó. Tương tự, chúng ta cũng thực hiện việc kiểm tra xem bình luận tồn tại hay chưa.
§ Class: DBCheck – dùng để kiểm tra dữ liệu trùng lắp bằng hash

o Lưu ý: Khóa của một shop là (tên + địa chỉ). Khóa của comment là (nội dung + người bình luận).
· Bước 2: Thực hiện hỗ trợ trích xuất dữ liệu
Chúng ta tạo một class có tên Crawler.java, cấu trúc như sau:

Trước tiên, chúng ta xây dựng hàm parseHTML:

o Hàm truyền vào 3 tham số
là ![]() của
trang cần lấy data, dấu hiệu bắt đầu (
của
trang cần lấy data, dấu hiệu bắt đầu (![]() )
và kết thúc (
)
và kết thúc (![]() )
của phần tài liệu sẽ lấy vì không phải lúc
nào chúng ta cũng lấy hết toàn bộ source html. Sau
đây là ví dụ:
)
của phần tài liệu sẽ lấy vì không phải lúc
nào chúng ta cũng lấy hết toàn bộ source html. Sau
đây là ví dụ:


Hình trên, chúng ta dễ dàng nhận thấy rằng chúng ta chỉ cần lấy danh sách các quán cà phê, trà sữa. Tất cả thông tin này chỉ nằm trong một đoạn html bắt đầu từ thẻ <div class=”result-item”> và kết thúc khi có thẻ <div class=”paging”>. Do đó, chúng ta chỉ cần cắt đoạn dữ liệu này về, sửa well-form. Việc xác định này sẽ giúp chúng ta vừa sửa ít nội dung và vừa nhanh hơn việc chúng ta phải xử lý trên toàn bộ html source.
o Biến ![]() trong
code sẽ giúp chúng ta đảm bảo chỉ lấy duy nhất
một đoạn trong tài liệu html, nếu có nhiều
đoạn có cùng
trong
code sẽ giúp chúng ta đảm bảo chỉ lấy duy nhất
một đoạn trong tài liệu html, nếu có nhiều
đoạn có cùng ![]() và
và
![]() .
.
o Tất cả nội dung
cào sẽ lưu vào chuỗi ![]() .
.
· Bước 3: Cào dữ liệu từ diadiemanuong
o Uri sẽ sử dụng:
“http://diadiemanuong.com/Search?q=&province=217&renderStyle=0&minPrice=0&maxPrice=5000000&getAllDistrict=true&productKind=20%2C109&p=”
o Giải thích: Để tìm tất cả các quán café, trà sữa ở thành phố hồ chí minh.
§ Chúng ta có thể lấy được link này từ tùy chỉnh trong bộ search của diadiemanuong. Tiếp theo, chúng ta nhấn chọn khu vực TP. HCM và category là cà phê, trà sữa.
§
Vì
trang sử dụng ![]() nên lần cào đầu
tiên ta cần lấy được số trang của nó
trước rồi mới vào từng trang lấy dữ liệu.
Số trang được lưu trong chuỗi có chứa data-page-index
của html source, chúng ta sẽ tách con số này ra. Nếu
site có nhiều page thì chúng ta sẽ chọn số lớn nhất
để lấy được tổng trang của toàn bộ
site đang cần xử lý.
nên lần cào đầu
tiên ta cần lấy được số trang của nó
trước rồi mới vào từng trang lấy dữ liệu.
Số trang được lưu trong chuỗi có chứa data-page-index
của html source, chúng ta sẽ tách con số này ra. Nếu
site có nhiều page thì chúng ta sẽ chọn số lớn nhất
để lấy được tổng trang của toàn bộ
site đang cần xử lý.
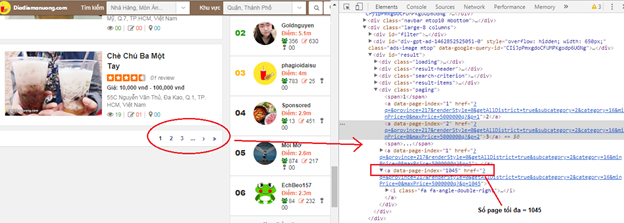
§ Lúc này, chúng ta thay đổi code hàm cào để có thể xử lý kết quả tốt hơn.
§ Chúng ta sẽ thêm một biến để lưu số page (pageCount), và một hàm tách chuỗi (phương thức updatePageCount) để lấy số page.
Ta có hàm updatePageCount trong Crawler.java:

§
Đối
với hàm cào dữ liệu, chúng ta thực hiện việc
thay đổi với việc thêm code gọi hàm ![]() trong hàm
trong hàm ![]() . Ở đây, chúng
ta chỉnh sửa lại thành hàm xử lý có tên gọi là parseHTML_getPageCount
. Ở đây, chúng
ta chỉnh sửa lại thành hàm xử lý có tên gọi là parseHTML_getPageCount

Tiếp theo, chúng ta cần hiện thực một class sử dụng bộ StAX Parser để trích dữ liệu và bỏ vào JAXB Obj có tên StaxParser.java:
Việc
dùng ![]() để lấy
dữ liệu từ tài liệu ra đã có rất nhiều
bài viết (tham khảo tại địa chỉ http://www.kieutrongkhanh.net/search/label/XML%26Java
) nên chúng tôi xin lướt qua nội dung này.
để lấy
dữ liệu từ tài liệu ra đã có rất nhiều
bài viết (tham khảo tại địa chỉ http://www.kieutrongkhanh.net/search/label/XML%26Java
) nên chúng tôi xin lướt qua nội dung này.
Ở đây, chúng tôi giới thiệu về chức năng các hàm trong class để quí vị tiện việc theo dõi tài liệu ở các nội dung tiếp theo:
· getReader: hàm truyền vào một chuỗi content và parse nó qua một XMLEventReader
· parseComment: truyền vào một nội dung well-form, lấy nội dung các bình luận trong các thẻ ra lưu vào một ListComment.
· parseShopInfo: truyền vào một nội dung well-form, lấy thông tin các shop trong các thẻ và lưu vào một ShopList.
· getUrlShop: truyền vào một nội dung well-form là kết quả tìm kiếm trên foody và đọc nội dung trả về một url nếu thông tin quán đó đúng với thông tin ta mong đợi (địa chỉ và tên quán giống nhau)

Mọi việc hỗ trợ cho việc xử lý đã hoàn tất, cụ thể là các class hỗ trợ việc cào và parse html source. Bây giờ, chúng ta thực hiện việc trích xuất dữ liệu. Bắt đầu từ đây, các nội dung xử lý sẽ được hiện thực hết trong hàm main của class MainCraw.java.
· Chúng
ta cần thực hiện lấy được ![]() khi chạy lần
đầu tiên
khi chạy lần
đầu tiên

§ Sau khi lấy được số page, chúng ta vào từng page để cào dữ liệu:

o Lưu ý
§
Số
page có thể rất lớn (khoảng trên ![]() ) nên lời khuyên là
thay vì duyệt
) nên lời khuyên là
thay vì duyệt
![]() các bạn nên để
giới hạn
các bạn nên để
giới hạn ![]() nhỏ, chẳng hạn
nhỏ, chẳng hạn
![]() dể dễ dàng
debug và testing mà không cần đợi cào một lượng
dữ liệu lớn về.
dể dễ dàng
debug và testing mà không cần đợi cào một lượng
dữ liệu lớn về.
· Bước 4: Kết hợp công cụ search trên foody
o Hàm search của foody sẽ có cú pháp như sau:
https://www.foody.vn/ho-chi-minh/food/dia-diem?q=
o Chúng ta thực hiện ghép các tên quán cào được ở diadiemanuong vào uri trên. Ví dụ như hình bên dưới:

o Bộ search foody khá tốt nên bạn có thể gắn tên tiếng Việt vào để search bình thường
o Một cách để giúp kết quả tìm chính xác hơn đó là tiền xử lý tên quán trước như bỏ dấu tiếng Việt đi, chuyển hết thành chữ thường.
Ý tưởng tiếp cận để lấy dữ liệu từ trang foody đã thể hiện ở trên sẽ định hướng cho chúng ta hiện thực tiếp việc xử lý lấy thông tin các quán ăn sau khi đã lấy được tên quán. Chúng ta tiếp tục hiện thực tiếp tục trong hàm main của phần cào dữ liệu từ web về.

§
Tạo
một danh sách các bộ comment song song với ![]() , nghĩa là
, nghĩa là ![]() thì sẽ có bộ
comment là
thì sẽ có bộ
comment là ![]() .
.
§
Sau
đó tạo ![]() search bằng cách
ghép tên quán sau khi chuyển thành raw, chú ý các khoảng trắng
cần thay bằng %20 để có thể lấy được
html source.
search bằng cách
ghép tên quán sau khi chuyển thành raw, chú ý các khoảng trắng
cần thay bằng %20 để có thể lấy được
html source.
§ Lấy source html và dùng stack chỉnh well-form. Ở đây chỉ khác là khi bỏ vào StAX Parser cần thêm một bước kiểm tra xem dữ liệu đó có khớp với thông tin quán mình không nên sẽ truyền vào tên (tagSearch) và địa chỉ (tagAddress).
§
Kiểm
tra xem kết quả search có khớp với trong hàm ![]() :
:
· name là tên quán chúng ta trích ra được.
· crawAdd là mảng chứa thông tin địa chỉ quán mà chúng ta đang xét.
· addObj = tagAddress.split(“;”)

· Điều kiện kiểm tra là 80% tên trùng hoặc ¾ thành phần địa chỉ giống nhau.
· Bước 5: Vào đường dẫn trực tiếp sau khi search để lấy được các bình luận:
Trở lại viết tiếp code trong hàm Main, lúc này chúng ta đã parse để lấy được url của shop. Nếu nó không rỗng và khác null thì chúng ta tiếp tục xử lý:

o Với url của shop, chúng ta chỉ cần thêm “/binh-luan” vào. Các thao tác vẫn giữ nguyên là: đánh dấu mở, đóng để lấy một phần html source, chỉnh well-form bằng stack (hàm fixstring), rồi dùng StAX parser lấy được comment trên tài liệu.
o
Với
kết quả xử lý được, chúng ta lưu tất
cả comment vào![]() . Sau đó, chúng ta đưa
vào
. Sau đó, chúng ta đưa
vào ![]() .
.
· Bước 6: Kiểm tra trùng lắp dữ liệu bằng hash và đưa vào database
o Sau khi có tất cả dữ liệu, chúng ta lưu trữ dữ liệu vào database. Chúng ta đã xây dựng việc kiểm tra trùng, bây giờ chúng ta chỉ việc duyệt hết danh sách các shop và các comment, nếu chưa có thì thêm vào database.
Dưới đây là phần code cuối cùng của hàm main để làm những việc lưu database như đã nói trên:

Đây là thành quả của chúng ta sau khi chạy hàm main:
Bảng dbo.shop

Bảng dbo.comment

·
Chúng
ta đã hoàn thành việc lấy dữ liệu các quán cà phê,
trà sữa và những bình luận tương ứng các quán
bằng việc kết hợp giữa hai trang ![]() và
và ![]() .
.
Chúc mừng quí vị đã có thêm sự lựa chọn và xử lý dữ liệu trong quá trình lấy dự liệu từ các trang web khác, đặc biệt với các trang web động mà không cần sử dụng các framework phức tạp.
Rất mong sự đóng góp của quí vị về chủ đề này và các phương pháp ý tưởng nhằm tạo thuận lợi nhất trong việc mining dữ liệu từ các web site đê lấy thông tin phân tích
Hẹn gặp quí vị ở các chủ đề khác
bài viết hay quá .Tks ad
Trả lờiXóa