Tác giả: Phạm Huy Hoàng
Mục đích: Chủ đề của bài viết này hướng dẫn cách thực hiện Web Scrapping (Parse dữ liệu từ website) trong các ứng dụng thực tế. Chúng tôi sẽ mô tả những nội dung cơ bản của Web Scrapping, cùng với những thư viện và tools hỗ trợ.. cho đến hiện thực một ứng dụng cụ thể.
Yêu cầu về kiến thức cơ bản
- Nắm vững khái niệm về ngôn ngữ lập trình Java, lập trình thao tác hướng đối tượng, sử dụng các method hay function
- Nắm vững khái niệm về cách sử dụng XPath (tham khảo lại bài Giới thiệu về XPath https://www.kieutrongkhanh.net/search/label/XML )
- Nắm vững và đã sử dụng tốt cách truy vấn sử dụng Xpath
- Có kiến thức cơ bản về HTML, javascript (Không cần có kiến thức nhiều về CSS).
Tools sử dụng:
· Netbeans 6.9.1
· JDK 6 update 22
· Trình duyệt: Chrome hoặc Firefox
· Thư viện: HtmlUnit
Một số khái niệm cơ bản:
Web scraping (Hay còn gọi là web harvesting hay web data extraction) là 1 phương pháp kĩ thuật dùng để lọc dữ liệu từ website. Mục tiêu của web scraping: Biến đổi dữ liệu không cấu trúc (HTML) thành dữ liệu có cấu trúc, để lưu trữ và phân tích trong DB.
Ứng dụng của web scraping:
· So sánh giá mua hàng online.
· Tích hợp thông tin website.
· Lấy dữ liệu của website khác.
Một số phương pháp web scraping:
· Phương pháp cơ bản nhất: Copy paste hoặc gõ lại bằng tay. Trong nhiều trường hợp đây là cách duy nhất và khả thi nhất.
· Sử dụng Regular Expresion Matching.
· Sử dụng thuật toán Data Mining.
· DOM Parsing hoặc HTML Parsing.
Thư viện chúng ta sử dụng hỗ trợ cho việc Web Scrapping là: HtmlUnit (http://htmlunit.sourceforge.net/)
Đây là 1 thư viện: "GUI-Less browser for Java programs". Lý do sử dụng
· API của nó khá mạnh, cho phép chúng ta điền thông tin form, submit form, click link.
· Hỗ trợ tốt javascript (Còn 1 số vấn đề nho nhỏ với jquery 2.0 trở lên).
· Có thể giả lập được IE, Firefox và Chrome.
· Đây là 1 trong những bộ Web Automation Testing khá tốt, có khả năng cạnh tranh được với Selenium.
Các bước thực hiện.
Tạo project Java Application
Tải thư viện HtmlUnit tại: http://sourceforge.net/projects/htmlunit/files/htmlunit/2.13/htmlunit-2.13-bin.zip/download
Giản nén, vào thư mục lib ta được
Copy thư mục lib này vào project, add toàn bộ các file jar thành library

Để test thử thư viện, ta viện 1 đoạn code nho nhỏ, lấy html của google.com
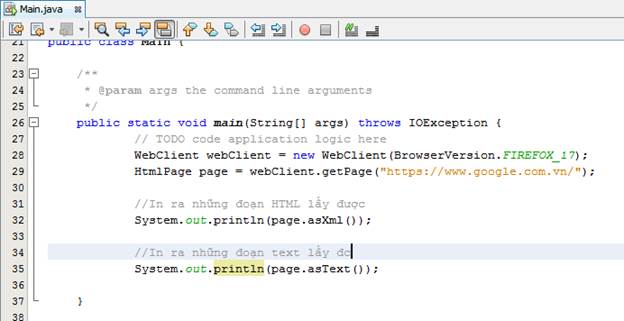
Kết quả:
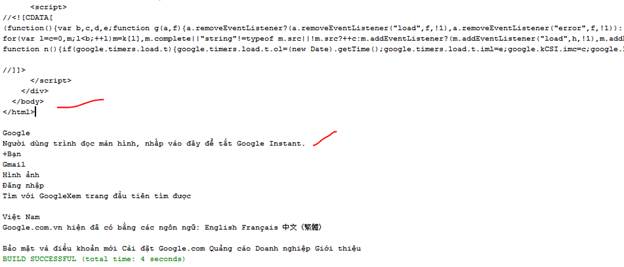
Những hàm trên là kết quả của 2 hàm asXML và asText.
Ngoài ra, có 1 sự khá khó chịu là, khi HTML Unit chạy, nó sẽ ghi ra vô số log dưới console
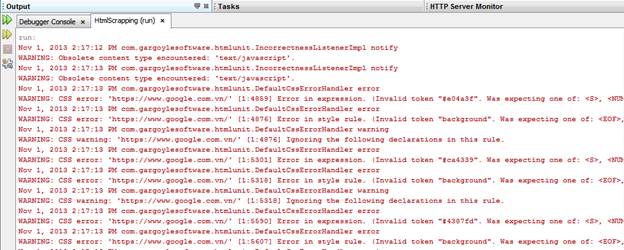
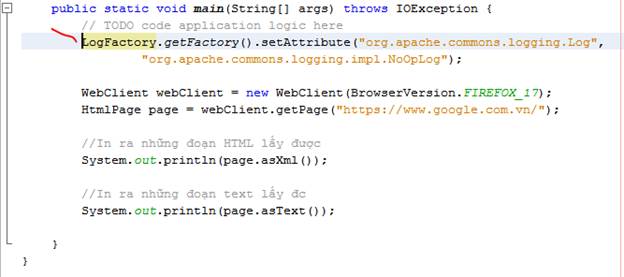
Để khắc phục, ta thêm dòng code này vào phía trên cùng
Mục tiêu của bài demo này: Parse toàn bộ sản phẩm của trang web http://dienmay.com/
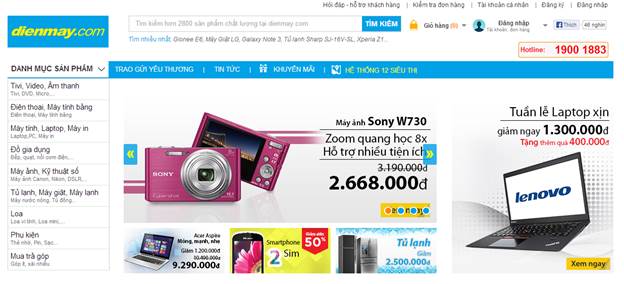
Lý do:
· Cấu trúc web khá đơn giản. Category ® Product
· Ko có paging
· Các div chứa thông tin đặt tên dễ đọc, html rõ ràng
· Javascript không gây ảnh hưởng nhiều tới việc lấy thông tin và parse
Hướng tiếp cận:
1. Từ trang chủ, ta lọc ra các category hàng hóa cùng đường dẫn.

2. Với mỗi category, ta sẽ vào trang của category đó, lấy thông tin của các sản phẩm về. Thông tin sản phẩm cần quan tâm là: Tên, giá cả, link ảnh, link sản phẩm
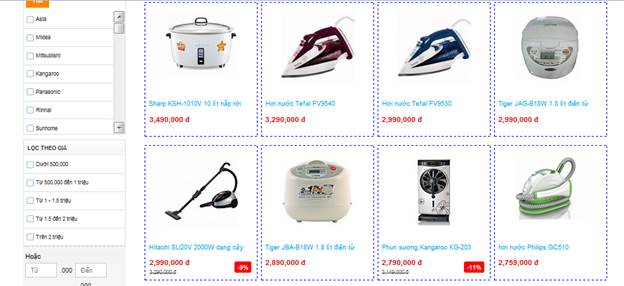
3. Tuy Html Unit hỗ trợ nhiều, nhưng việc lọc và parse DOM element sẽ được thực hiện 90% bằng Xpath, nhằm dễ dàng tái sử dụng về sau, tránh việc viết lại code.
(Nếu muốn thử thách, sau khi làm xong bài demo này, quý vị có thể thử parse 1 số trang bán voucher: hotdeal, muachung, cungmua… Các div chứa thông tin được sắp xếp lung tung, chồng chéo, đặt tên không rõ ràng, sẽ là một thử thách không nhỏ với khả năng viết Xpath của quí vị).
Note:
Để cho dễ dàng hơn, quý vị nên sử dụng trình duyệt firefox, lần lượt cài 2 add-on Firebug và Firepath dưới đây:
https://addons.mozilla.org/vi/firefox/addon/firebug/
https://addons.mozilla.org/en-US/firefox/addon/firepath/
Firebug chỉ là bộ developer tool bình thường của Firefox. Với Firepath, ta có thể test Xpath, Jquery, CSS, Sizzle selector. Firepath sẽ highlight những element được chọn.
Cách sử dụng:
1. Nhấp chuột phải, chọn “Inspect Element with Firebug”.
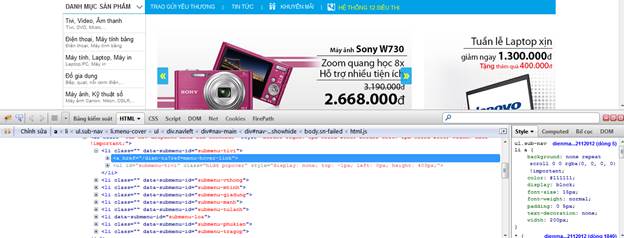
2. Bấm qua tab FirePath, chọn Xpath.
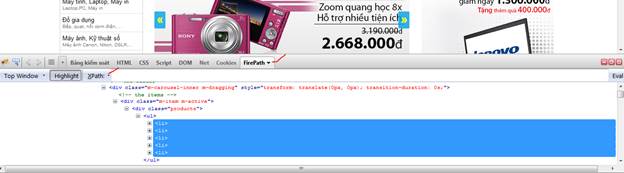
3. Đánh câu lệnh Xpath vào, bấm Eval, những element được chọn sẽ được highlight
Sau khi cài đặt + test xong, chúng ta tiếp tục quay lại với project hiện hành.
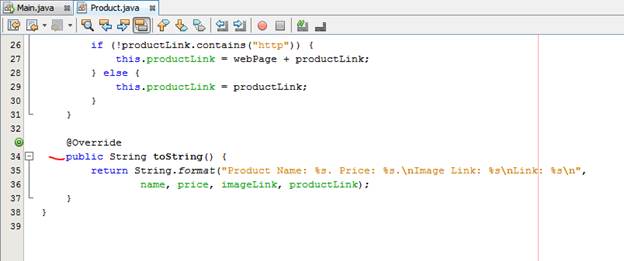
Ta tạo cái class pojo để chứa thông tin
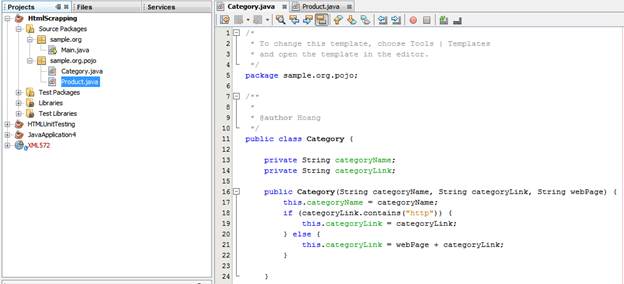
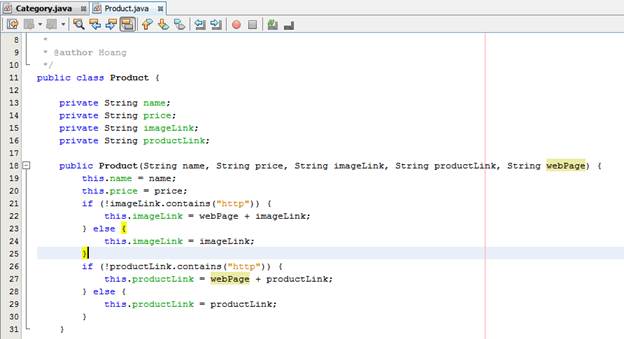
Ở nhiều trang web, link ảnh + link sản phẩm là relative url, trong khi đó ở 1 số trang khác lại là absolute url, do đó ta phải check, cộng thêm trong constructor của 2 class trên.
Tiếp theo, ta bắt đầu parse các category từ trang chủ dienmay.com. Nghiên cứu html, ta thấy
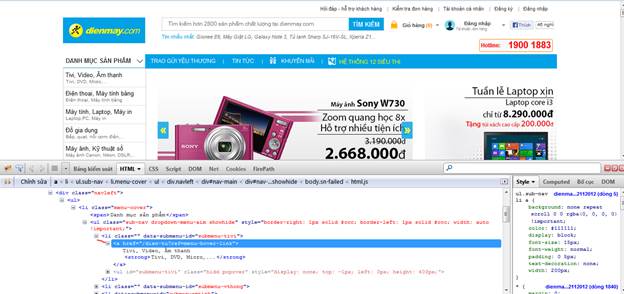
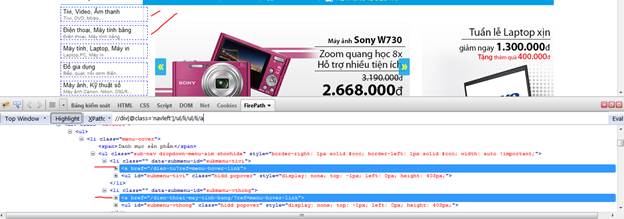
Đường link ta cần chọn nằm trong div có class=”navleft”, nằm sâu trong 2 lớp li,ul.
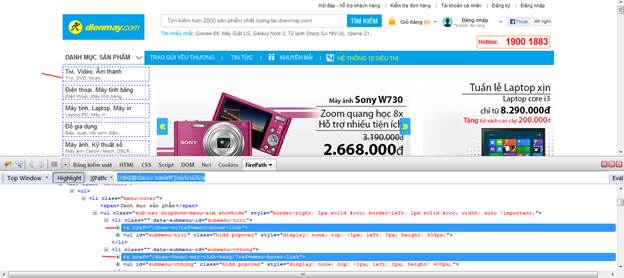
Ta viết được Xpath : //div[@class='navleft']/ul/li/ul/li/a
Test thử xpath này với FirePath
Ta viết code để lọc những link này ra như sau, quý vị đọc kĩ comment
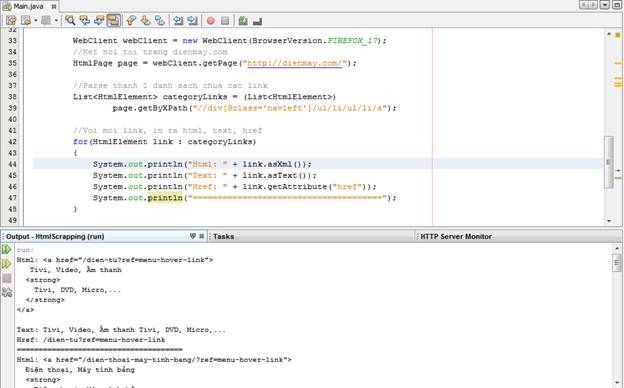
Ta tạo 1 danh sách chứa các category dựa theo link, quý vị sửa lại code
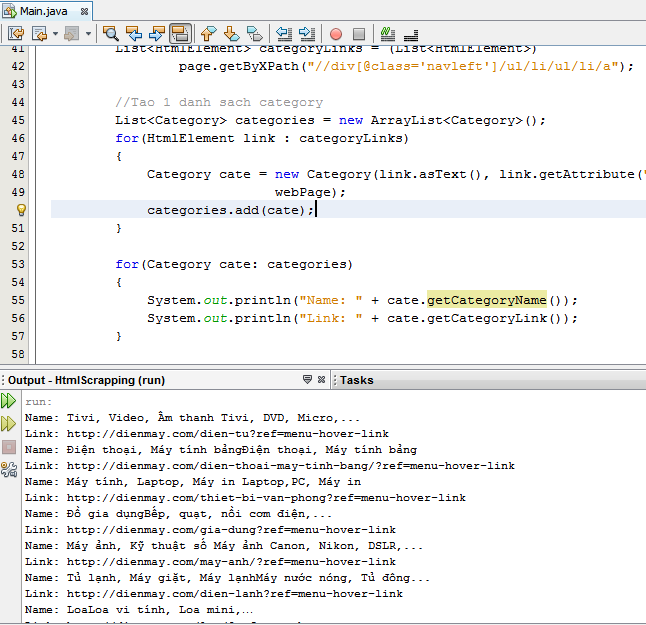
Chúng ta đã parse xong các category hàng hóa của dienmay.com. Trước khi thực hiện parse các sản phẩm, chúng ta quay trở lại, nghiên cứu cấu trúc html của trang.
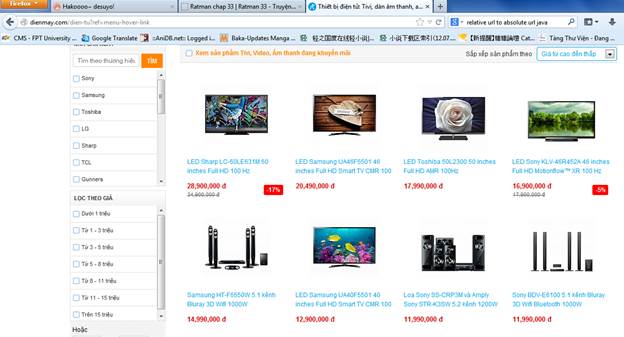
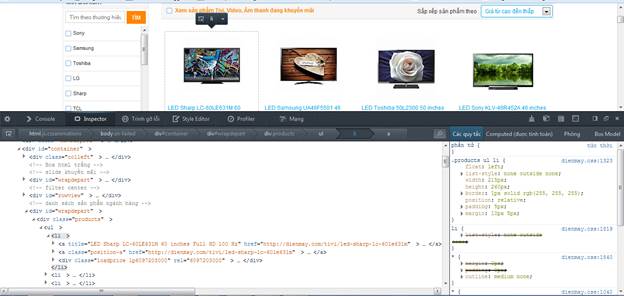
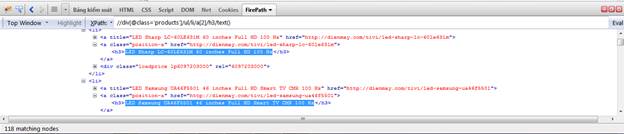
Dễ thấy, mỗi món hàng là một tag li, nằm trong div có class=’product’.
Câu lệnh Xpath: //div[@class='products']/ul/li
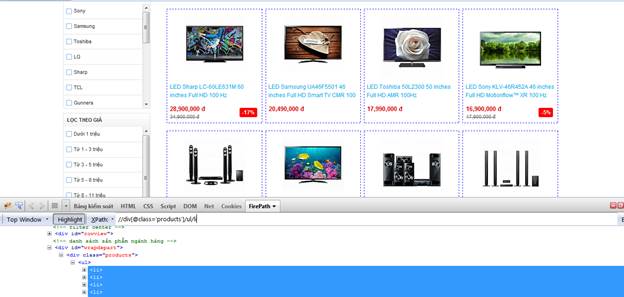
Với mỗi sản phẩm, chúng ta cần lấy tên, giá, link ảnh, link sản phẩm.
Tiếp tục phân tích HTML của 1 sản phẩm. 4 giá trị cần tìm của chúng ta
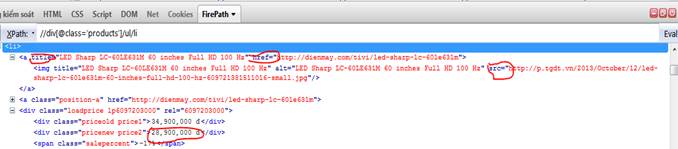
Lần lượt test chuỗi Xpath cho 4 giá trị
Tên sản phẩm
Link sản phẩm

Link ảnh

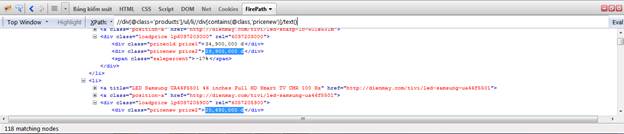
Giá
Nếu để ý kĩ, các bạn sẽ thấy có thể lấy tên sản phẩm dựa theo attribute title của link, tuy nhiên có nhiều trang web ko có title này.
Vì tên sản phẩm và giá thường là text node chứ không phải attribute như link, do đó ta select text node.
Quay lại code, giả sử ta muốn lấy danh sách sản phẩm của category đầu tiên.
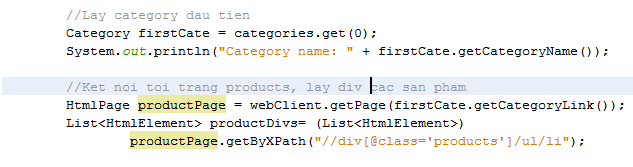
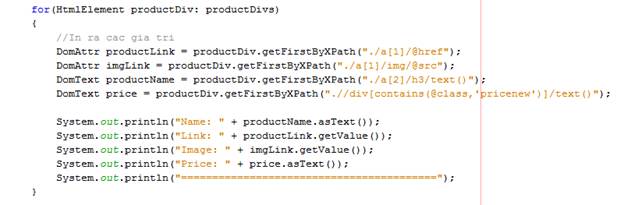
Quý vị để ý kỹ chuỗi XPath. Chuỗi Xpath này khác với Xpath khi text, bởi vì chúng ta truy vấn Xpath từ ngay trong div, do đó phải có dấu . ở đầu để chỉ rõ context truy vấn
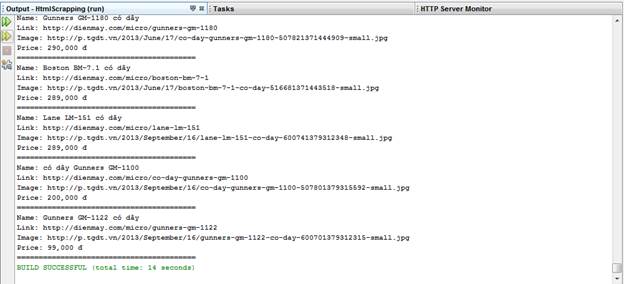
Kết quả chạy, ta có.
Cải tiến một chút, đưa các giá trị parse được vào 1 mảng chứa product, parse toàn bộ các category
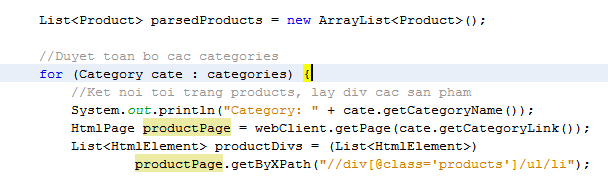
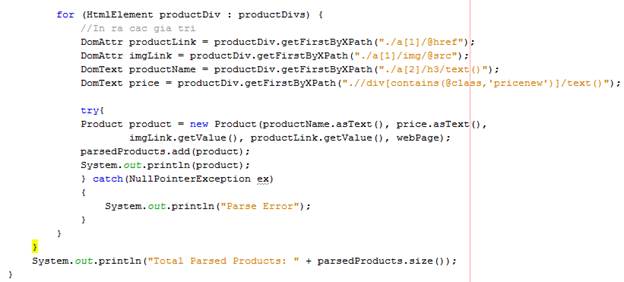
Ta bổ sung thêm try, catch, đề phòng trường hợp có node có html ko phù hợp, dẫn đến việc parse bị lỗi.
Chạy đoạn code trên, ta có:

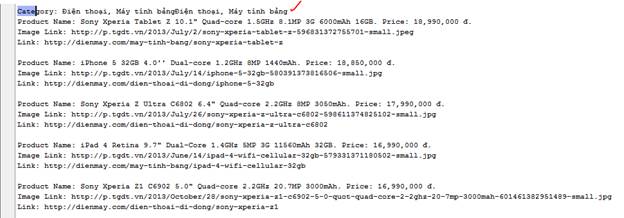
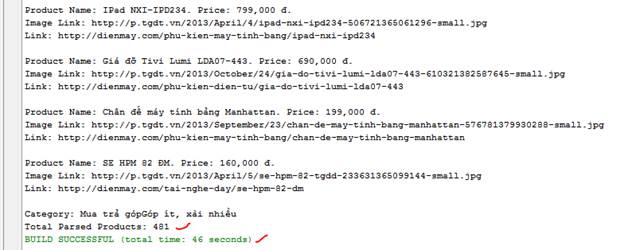
Chúc mừng quý vị đã hoàn thành xong phần 1 của bài Tutorial.
Ở phần 2, chúng tôi sẽ hướng dẫn quý vị tái sử dụng bộ Parser đã viết, dùng 1 bộ parser để parse nhiều trang web khác nhau, chỉ cần thay chuỗi Xpath. Phần 3 sẽ cố gắng có viết trong giới hạn cho phép nhằm dùng để hướng dẫn parsing 1 số các trang web phức tạp (Có paging, sử dụng javascript để load v…v)
3 trang web sample mà chúng ta sẽ parse trong topic tiếp theo:
http://www.worldsoccershop.com/

Không có nhận xét nào:
Đăng nhận xét