Sử dụng Selenium Web Driver để trích xuất dữ liệu từ website “động”
Tác giả: Hà Lê Duy Khang
Mục đích: Bài viết này hướng dẫn cách khai thác dữ liệu từ các trang website “động” (những website này sử dụng javascript hay jQuery để tạo front-end tương tác với người dùng) bằng thư viện Selenium Web Driver mà các thư viện thông thường như java.net, htmlUnit… không thể lấy dữ liệu được. Trong bài viết chúng tôi hướng dẫn cách phân tích (inspect element của web site) từ đó hướng tới cách tổ chức và khai thác dữ liệu trong quá trình xử lý
Yêu cầu về kiến thức cơ bản
▪ Nắm vững khái niệm về ngôn ngữ lập trình Java, lập trình thao tác hướng đối tượng, sử dụng các method hay function.
▪ Nắm vững khái niệm về XML, Parser và cách thức sử dụng các bộ Parser, cách sử dụng XPath để truy vấn dữ liệu trong tài liệu XML (#xml #xpath).
▪ Nắm vững về cách xây dựng ứng dụng web theo mô hình JavaEE, và cách kết hợp XML trong lúc xây dựng ứng dụng
▪ Nắm vững về cách xây dựng ứng dụng web theo mô hình JavaEE có kết nối DB và ứng dụng MVC2
▪ Nắm vững về cách xây dựng ứng dụng web đồng bộ dữ liệu với DB sử dụng JPA (tham khảo tại địa chỉ http://www.kieutrongkhanh.net/2016/08/ung-dung-jpa-vao-mvc2-ket-hop-javaee6.html )
▪ Có kiến thức cơ bản về HTML, JavaScript (Không cần có kiến thức nhiều về CSS).
Các công cụ yêu cầu:
· Netbeans 8.2.
· Tomcat Server 8.x
· Trình duyệt sử dụng là Chrome.
· Chrome Driver:
o Kiểm tra version của trình duyệt Chrome tại chrome://settings/help.
o Vào link https://sites.google.com/a/chromium.org/chromedriver/downloads để tìm driver phù hợp với version trình duyệt hiện tại đang sử dụng
o Thư viện Selenium: download tại http://www.seleniumhq.org/download/ (chọn Selenium Standalone Server, version hiện tại là 3.7.1).
Selenium WebDriver là gì?
Selenium Webdriver (Se driver) là một tool open source giúp việc thực thi các hành động lên trang web một cách tự động tùy vào mục đích và yêu cầu của người viết (những hành động này bao gồm: điền form, bấm nút gửi request…). Tool này có mục đích chính là để thực thi automation testing.
Tuy nhiên, Se driver có khả năng giả lập trình duyệt ứng dụng web (trong bài này, chúng ta sẽ sử dụng trình duyệt Chrome để áp dụng), chúng ta sẽ sử dụng Se driver để lấy dữ liệu từ các website dùng Javascript và jQuery mà các thư viện khác không hỗ trợ được.
Trong ví dụ dưới đây, chúng ta sẽ dùng Se driver để lấy được dữ liệu từ website https://fptshop.com.vn/ (cụ thể là lấy tất cả dữ liệu về các sản phẩm trên trang này).
Các bước thực hiện
Bước 1: Phân tích website cần lấy dữ liệu

Về tổng quan, menu của web site này bao gồm những loại sản phẩm: Điện thoại, Laptop, Apple, Samsung, Tablet, Phụ kiện, Máy đổi trả, Sim & thẻ.
Tuy nhiên, 02 menu Apple và Samsung là các sản phẩm được ánh xạ từ các mục Điện thooại, Laptop và Tablet. Vì thế, chúng ta sẽ bỏ qua 2 mục này trong quá trình xử lý.
Menu Máy đổi trả thì số lượng sản phẩm rất ít, menu Sim & thẻ thì không có dữ liệu về sản phẩm, cho nên chúng ta sẽ bỏ qua 2 mục này trong quá trình xử lý.
Tóm lại, chúng ta sẽ xử lý để lấy dữ liệu các sản phẩm từ 4 mục: Điện thoại, Laptop, Tablet và Phụ kiện.
Tiếp đến, chúng ta vào menu Điện thoại.
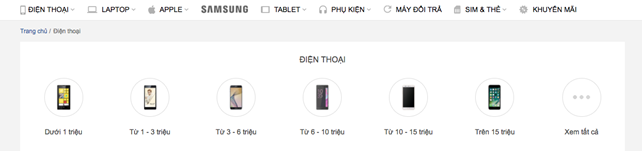
Chúng ta nhận thấy rằng tất cả điện thoại ở đây được chia theo phân khúc giá, và có một lựa chọn là “Xem tất cả” (Mục này sẽ hỗ trợ chúng ta tìm thấy tất cả các sản phẩm trong trang Điện thoại)
Tương tự cho menu Laptop và Tablet, cấu trúc tương tự với cấu trúc của menu Điện thoại. Đây là vấn đề cần thiết để chung ta có thể xác định bộ khung trong việc xây dựng bộ khai thác dữ liệu cho một trang web
Tiếp theo cho menu Phụ kiện, menu này chuyển vào trang với cấu trúc nội dung chia ra nhiều loại sản phẩm theo menu phía bên trái.

Sau khi đã xác định cấu trúc của trang cần xử lý, chúng ta chuyển sang bước tiếp theo để thực hiện lấy dữ liệu của trang web
Bước 2: Thực hiện Crawler để lấy dữ liệu
Chúng ta thực hiện tạo project Java Application thông thường và phát sinh tự động cơ chế đồng bộ dữ liệu với DB sử dụng JPA
Cấu trúc project cơ bản như sau

Trong đó:
· Crawler.java: Class hỗ trợ cào dữ liệu của trang web về để xử lý.
· Các class trong package data: Entity Object để hỗ trợ chúng ta đưa dữ liệu vào DB.
· Các class trong package function: Các function hỗ trợ thực hiện lưu các Entity Object vào DB.
· JPAUtility.java: đây là thư viện JPA giúp chúng ta thực hiện lưu trữ dữ liệu xuống DB.
Trong class Crawler, chúng ta sẽ khai báo 2 variable là driver và mainURL
· driver: đại diện cho Selenium WebDriver.
· mainURL: đại diện cho URL của trang web mà ta đưa vào parse.

· Phương thức setMainURL() sẽ hỗ trợ việc load website về bằng câu lệnh: driver.get(mainURL);
Đầu tiên, chúng ta sẽ lấy các link trên menu của website https://fptshop.com.vn/ để đến các trang con liên kết và lấy dữ liệu của các trang liên kết này.
· Một khi đã mở trang web lên trên browser, chúng ta click phải chuột, chọn Inspect, browser sẽ show cho chúng ta mã nguồn của trang web.

· Chúng ta nhận thấy rằng
o Các mục của menu đều nằm trong thẻ <li>. Các thẻ này nằm trong thẻ <ul> chứa các class là “fs-mnul clearfix”.
o Các đường link trong menu đều nằm trong thẻ <a> và thẻ <a> lại nằm trong thẻ <li>.

o Do đó, chúng ta sẽ lấy tất cả các link đó bằng đoạn code để lấy Category vào trong class Crawler.java như bên dưới

o Chúng ta sẽ sử dụng xpath để tìm thẻ a như sau
“//ul[@class='fs-mnul clearfix’]/li/a”
· Chúng ta vừa hoàn tất xong việc lấy các Category trên trang cần xử lý
Tiếp theo, chúng ta thực hiện việc lấy các sản phẩm trong từng Category.
Vì cấu trúc trang Điện thoại, Laptop và Tablet có những nét tương đồng nên chúng ta xây dựng hàm crawlType() để áp dụng cho cả ba.
· Thực hiện lấy các Link con để đi đến từng nhóm sản phẩm
o Các nhóm theo giá

o Mục “Xem tất cả”

· Hàm crawlType() là hàm được dùng chung để crawl cả 3 trang là Điện thoại, Laptop và Tablet. Chúng ta sẽ truyền tham số là link tương ứng để truy cập trang xử lý, class Object tương ứng để đón nhận kết quả xử lý cùng một số chuỗi truy vấn xpath để thực hiện xử lý dữ liệu tùy thuộc trang đang xử lý.
· Code được bổ sung vào class Crawler như sau

Tiếp đến, chúng ta sẽ xử lý lấy các sản phẩm trên từng trang. Chúng ta tìm hiểu cấu trúc của từng trang thông qua việc inspect element trang đó
· Trang điện thoại

· Trang Laptop

· Trang tablet
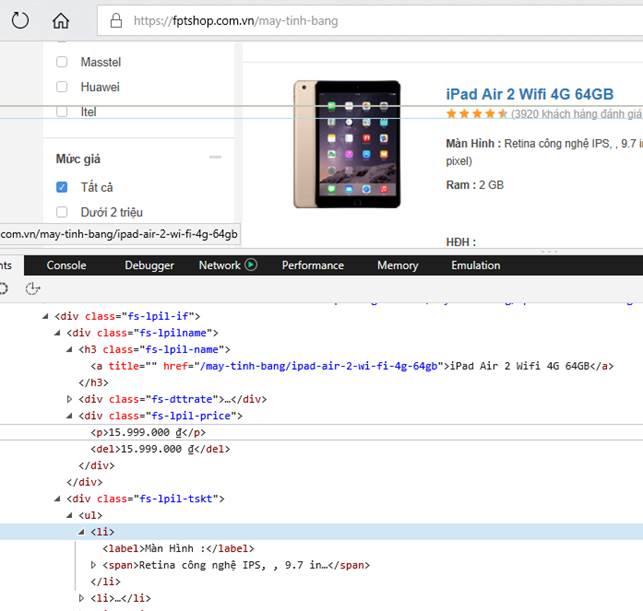
· 03 trang này chỉ có khác biệt chút ít về className của những thẻ chứa dữ liệu.
· Tuy 03 sản phẩm Điện thoại, Laptop và Tablet có những nét tương đồng nhưng giữa chúng vẫn có sự khác nhau. Vì thế, chúng ta nên tạo ra 03 bảng trên database tương ứng với 03 class Object trên bộ nhớ ứng dụng nhằm dễ dàng truy vấn và tối ưu hoá bộ nhớ.
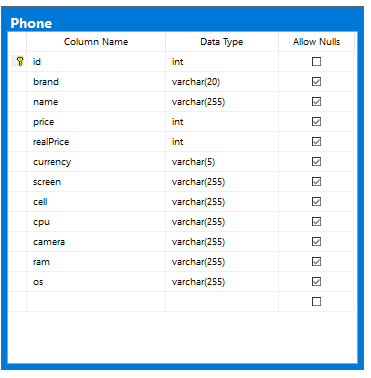

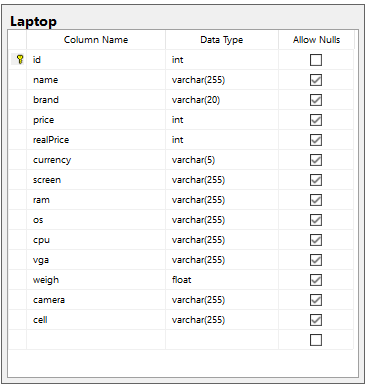
Tiếp theo, chúng ta thực hiện parse Category đầu tiên, đó là trang Điện thoại.
· Chúng ta thực hiện tìm hiểu cấu trúc của một sản phẩm

· Sau khi phân tích cấu trúc trang này, chúng ta sẽ tạo class Phone (Phát sinh Entity Class với JPA) như sau
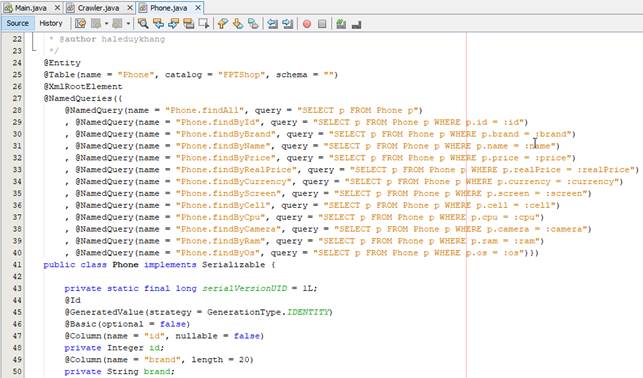


· Như nội dung đã phân tích trong phần đầu của bài viết, chúng ta cần phải click vào nút “Xem tất cả” để load được tất cả sản phẩm của Điện thoại.
· Tương tự cách phân tích đường dẫn XPath lấy Category, chúng ta tìm được đường dẫn của link “Xem tất cả”. Sau đó, chúng ta sẽ load trang “Xem tất cả”.
o Về tổng quan, chúng ta sẽ thấy trang “Xem tất cả” như sau:
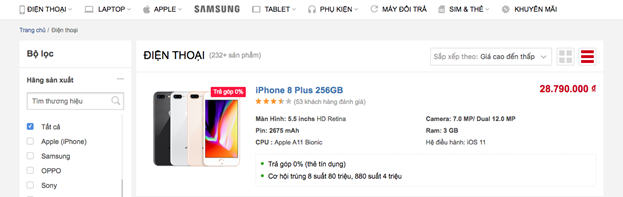
· Trang này có tất cả sản phẩm và được đánh số trang ở phía dưới. Đến đây, chúng ta phải tìm cách duyệt để lấy tất cả các sản phẩm trên.

o Chúng ta bắt đầu phân tích các button đánh số trang

o Chúng ta dễ dàng nhận ra rằng, tổng số sản phẩm sẽ nằm trong thuộc tính “data-total”, trang hiện hành sẽ có class = “active”.
o Do đó, chúng ta sẽ lấy dataTotal thông qua việc bổ sung code cho hàm crawlType như sau

· Vẫn bằng cách phân tích html, chúng ta thấy rằng mỗi sản phẩm đều nằm trong thẻ div có class = “fs-lpil”. Từ đó, chúng ta sẽ lấy được các thông tin về sản phẩm trong thẻ div đó.

· Chúng ta sẽ duyệt trong khi currentTotal còn nhỏ hơn dataTotal. Đoạn code bổ sung tiếp theo trong phương thức crawlType dưới đây giúp ta lấy được Product brand, name và price.


o Code trong mục trên đang sử dụng cơ chế Reflection của Java để có thể gọi hàm của một class bất kỳ mà không cần gọi trực tiếp phương thức cụ thể
· Hai đoạn code sau đây dùng để lấy các thông tin khác của Product. Khi lấy được hoàn tất thông tin của một Product, ta sẽ lưu xuống database. Sau khi duyệt hết list items thì ta sẽ cập nhật lại giá trị của currentTotal.
o Thực hiện bổ sung code vào hàm crawlType trong class Crawler



· Phương thức add của class Phone như sau


· Tiếp theo, chúng ta sẽ lấy số trang hiện tại để từ đó tìm số trang tiếp theo để có thể load tiếp các sản phẩm. Code được bổ sung thêm vào hàm crawlType như sau

· Lưu ý
o Chúng ta sẽ tìm ra button để đến trang kế tiếp, và click vào button đó. Nếu như currentPage là page cuối cùng thì ta sẽ không tìm ra được button, do đó sẽ xảy ra exception. Tuy nhiên, khi xảy ra exception, chúng ta đã lấy được toàn bộ dữ liệu, và khi đó ta thoát vòng lặp.
o Hàm waitForJSToLoad() hỗ trợ việc xử lý chờ cho đến khi thao tác load trang bằng JavaScript/jQuery thành công khi button được click để chuyển trang (button trên trang web thực hiện load trang bằng code JavaScript hoặc jQuery). Nếu chúng ta không thực hiện điều này thì chương trình đang chạy sẽ gây nên lỗi crash bởi vì cây DOM cũ đã bị xoá nhưng cây DOM mới chưa load kịp dẫn đến hệ thống không tìm thấy các Web Element như khi trang đã load đầy đủ. Chi tiết hàm waitForJSToLoad() trong class Crawler như sau:

Đến đây, chúng ta đã parse tất cả sản phẩm của trang Điện thoại.
Hai trang Laptop và Tablet cấu trúc tương tự như trang Điện thoại nên chúng ta chỉ cần sửa các tham số truyền vào hàm crawlType() thì chúng ta sẽ lấy được dữ liệu của hai trang trên.
· Code thực hiện của phương thức crawlProduct được thực hiện trong class Crawler như sau

· Cấu trúc của class Table và Laptop được phát sinh như sau






· Các class hỗ trợ tương ứng để lưu trữ xuống DB cho 02 thành phần laptop và tablet như sau




Cuối cùng, chúng ta thực hiện parse tất cả sản phẩm từ trang Phụ kiện vì nó có cấu trúc khác 3 trang đã nêu trên.
Trang Phụ kiện có menu nhỏ phía bên trái, chúng ta phải lấy cái link đến từng Category trong menu đó.
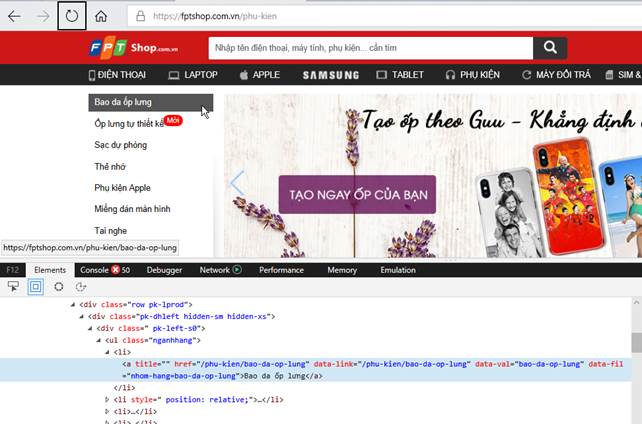
Code được thực hiện với hàm crawlAccessories được bổ sung vào class Crawler như sau

Với từng loại sản phẩm trong trang phụ kiện,
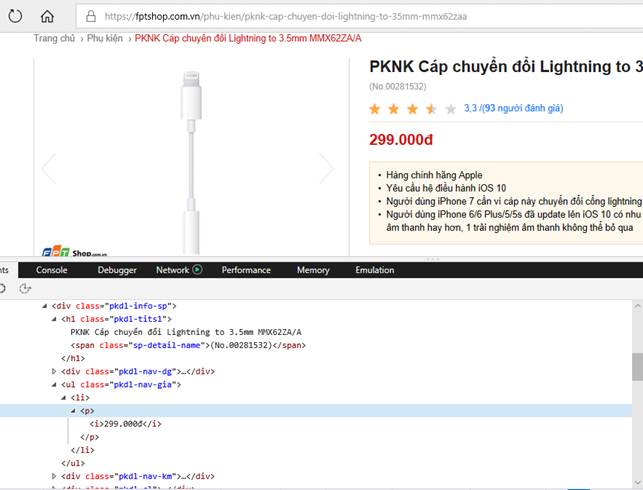
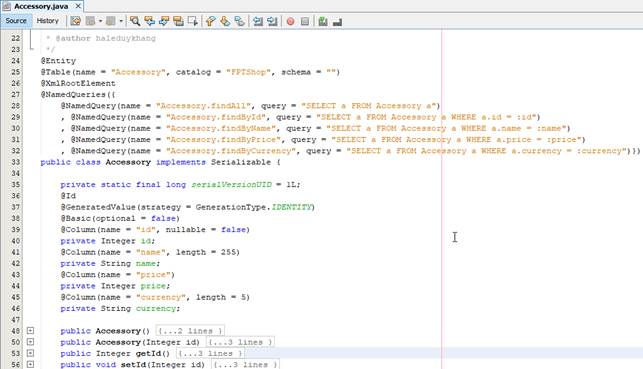
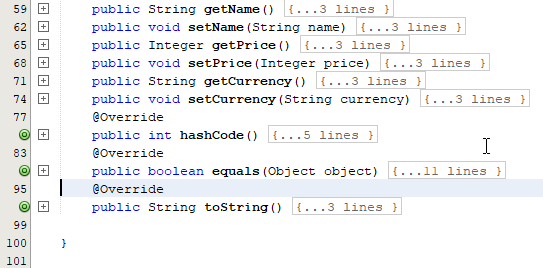
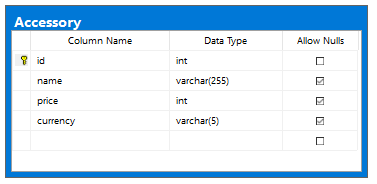
Chúng ta xây dựng class Accessory tương ứng với tổ chức DB để lưu trữ dữ liệu như sau
Sau đó, chúng ta đến từng Category thì thấy rằng những Category có nhiều sản phẩm thì sẽ có button “Xem thêm…”

Do đó, khi đến mỗi Category, chúng ta sẽ phải click button “Xem thêm…” đến khi nào nó mất để có thể load tất cả sản phẩm của từng Category.
Với lưu ý nêu trên, chúng ta sẽ bổ sung code cho hàm crawlAccessories tiếp tục ở trên để parse tất cả các sản phẩm trong từng Category.
· Button “Xem thêm…” có class = “loadmore”, cho nên khi click button “Xem thêm…”, chúng ta phải đợi cho JavaScript/jQuery load lên hoàn tất bằng hàm waitForJStoLoad().
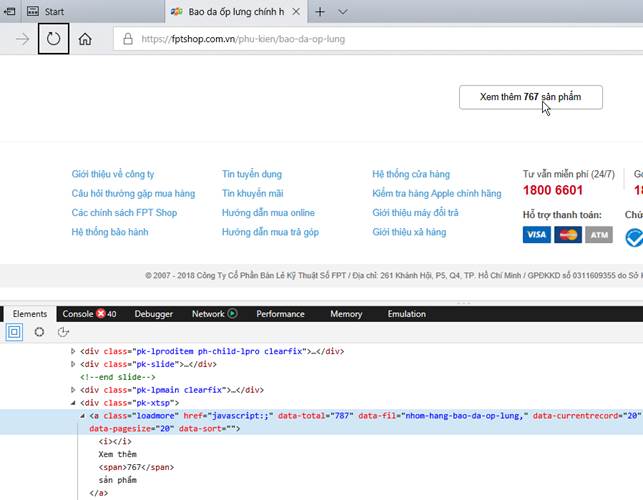
· Code bổ sung cho phần hàm crawlAccessories như sau

· Bổ sung code cho phần hàm crawlAccessories để lấy các thành phần accessory để đưa vào DB

Các phương thức trong Class AccessoryFuction

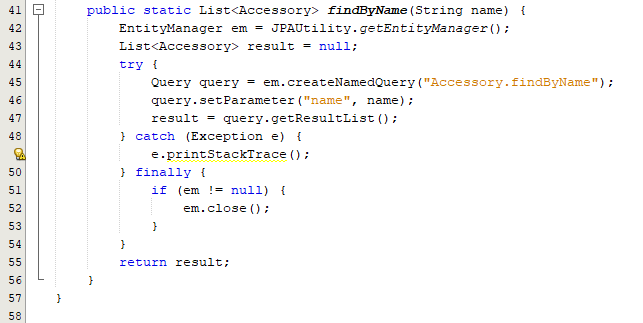
Cuối cùng là cấu trúc class Main.
· Hàm setDriverProperty() dùng để set Chrome Driver đã download ở phần chuẩn bị. File chromedriver này phải được add vào trong lib của project.

· Code của class Main dùng để test thử những gì chúng ta đã làm ở trên

· Các thành phần hỗ trợ kết nối DB sử dụng JPA trong project như sau


· Cấu trúc Project hiện hành như sau
Đến đây thì chúc mừng quí vị đã hoàn thành việc dùng Selenium Web Driver để parse website “động”. Chúng tôi hy vọng quí vị sẽ sử dụng dữ liệu được xử lý vào những mục đích hữu dụng và hợp pháp.
Rất mong những đóng góp chân thành của quí vị về nội dung bài viết này.
Bài viết công phu quá :D Cảm ơn thầy nhiều :D
Trả lờiXóaBài viết hay quá chỉ tiếc em đọc còn chưa hiểu, do bản thân học PHP nên hơi xoàng :(
Trả lờiXóa